


Доклад Светланы Бурлак — доктора филологических наук, профессора РАН, ведущего научного сотрудника Института востоковедения РАН, автора книги «Происхождение языка» на Форуме «Ученые против мифов-7».
Добрый день. Я сегодня буду говорить о мифах связанных с санскритом. Основу этих мифов, по видимому, составляет история о том, как санскритолог Дурга Прасад Шастри в 60-х годах приехал в Россию, поехал в какую-то северную деревню и изумился: боже, как русский похож на санскрит! Прямо хоть без переводчика!

И из этого дальше происходят вот такие удивительные мифы, вплоть до домашних упряжных мамонтов, исходящие из того, что русский язык — это диалект санскрита / предок санскрита / потомок санскрита (причем прямой). И виманы, которые тут уже упоминались, тоже где-то там летать должны. Ну, подробно эти сказки я рассказывать не буду – вы можете их легко найти в интернете. А я буду рассказывать о том, насколько санскрит действительно похож на русский.
Итак, если санскрит действительно похож на русский, настолько, что можно обойтись без переводчика — ну, вперёд:

Это отрывок из истории про Наля и Дамаянти: Наль собирался идти свататься к Дамаянти, тут встретились ему четыре бога и решили, мол, давайте мы его попросим, наоборот, нас Дамаянти порекламировать. Наль увидел четырёх богов и сказал, мол, просите, что хотите, я исполню любую вашу просьбу. А потом всё-таки спросил, в чём просьба-то состоит (то есть, сначала пообещал, а потом спросил, что, собственно, делать).
Кто из здесь присутствующих, не учивших санскрит, способен опознать, какому фрагменту того, что я сейчас рассказала, соответствует то, что здесь написано?

Ну вот, из неучивших санскрит, видимо, никто, поэтому основание мифа (что санскрит и русский прямо такие близкие и понятны без перевода) рушится. Ну, а дальше рушится и всё здание мифа (поэтому я о нём так долго и не рассказывала).
И это, кстати, при том, что тут не то, что корни, тут суффиксы и приставки иногда похожи! Вот, посмотрите:
● t- в слове tebhyah – это тоже самое т, которое у нас в указательном местоимении тот. Я даже не удивлюсь, если е тоже самое (гласный е – это в санскрите бывший дифтонг; у нас, соответственно это «ять» — тоже бывший дифтонг).
● prati- – это тот же элемент, что у нас проти(в). Приставка это или наречие – это уже зависит от того, куда оно встанет, но этимологически это тоже самое.
● jñā- – это тот же корень, что и зна(ть);
● pari- – приставка, соответствует нашему пере-;
● prach- соответствует нашему корню (с)прос(ить);
● sthā- соответствует нашему сто(ять);
● kar- (мы видим его в karisya (каришья) в первой строке, а ещё – вот это kṛ в слове kṛtāñjalir (кританджялир) во второй строке) с большой вероятностью соответствует нашим чар(ам).
В санскрите kar- – это просто ‘делать’, это тот же корень, что и в самом слове санскрит. Потому что само слово санскрит (samskṛta-) буквально значит ‘сделанный, обработанный’. Бывает пра-крит, а бывает санс-крит. Пракрит – это такой деревенский необработанный язык на котором говорят всякие простолюдины, а санскрит – это литературный стандарт. Поэтому он такой обработанный. (Собственно, как и любой литературный язык – обработанный, удивительно, да?)
А вот это i(ti), возможно, соответствует тому [j], который не виден в качестве отдельной буквы, но слышен в качестве отдельного звука в таких словах как его, её, ей, ему и т. д.
В целом строчки переводятся так:

«Тем <богам> пообещав» (pratijñā- – это ‘обещать’), «Наль» (это его так зовут) «Сделаю!» (karisya), iti – это маркер окончания прямой речи.
И тут есть ещё одно забавное сходство с русским языком. Самый точный перевод этого фрагмента был бы такой: «Им пообещав, Наль такой: сделаю!» Вот у нас такой — это указательное местоимение, указывающее на прямую речь, в современном разговорном русском оно довольно часто употребляется.
bbhārata
«о, Бхарата!» – поскольку история рассказывается внутри Махабхараты одному из героев, который потомок Бхараты, то вот это обращение к потомку Бхараты. Кстати, возможно, что это тот же корень, что и русское бер(у) (а может быть и нет, потому что имена собственные этимологизировать трудно, может они отсюда, а может, и нет вовсе).
aathai ’tān paripapraccha kṛtāñjalir upasthitah
atha — значит ‘потом’, ’tān – ‘у них’ (etan, которое в сочетании с atha превращается в athai’tān) «спросил с почтительно сложенными руками (āñjali)», āñjali (анджяли) – слово без этимологии, не знаю, откуда оно взялось; kṛtāñjalir значит ‘со сделанным āñjali’, upasthitah — ‘представший, приблизившийся’ к ним (upa- — если кто знает греческий, то это похоже на греческое слово ὑπο (хюпо); мы его, кстати, знаем из русского, только в русском оно заимствовалось и выглядит как гипо-, а на самом деле оно «хюпо»).
Так что санскрит, конечно, похож на русский, но вовсе не в том смысле, чтобы можно без переводчика всё сразу читать. На самом деле, ощущение, что санскрит похож на русский (или в обратную сторону – русский похож на санскрит, или санскрит похож на что-нибудь ещё), возникает у любого человека, который знаком с древними (или достаточно архаичными, как русский или литовский) европейскими языками, когда он внезапно знакомится с санскритом.
И, собственно говоря, сама наука индоевропеистика началась с того, что Уильям Джоунз познакомился с санскритом. И если бы тогда в моде были заголовки, как сейчас, то английские газеты выходили бы со словами: «Учёные в шоке! Санскрит похож на латынь (на греческий / на любые другие языки)!» На любые европейские языки, знакомые образованному филологу – на готский, на немецкий, на английский.

И, соответственно, Уильям Джоунз в этой своей работе показал родство санскрита с языками Европы — как раз с латынью, греческим, готским, английским, немецким, персидским (который он до этого тоже поучил) и кельтскими языками. Потом Расмус Раск добавил ещё балтийские и славянские языки – и оказалось, что эти дикие восточные варвары тоже относятся к «индогерманской» (как тогда говорили) языковой семье.
(Да, с точки зрения германцев славяне — это предмет рассмотрения института востоковедения. Наш московский Институт востоковедения, где я работаю, славянами уже, естественно, не занимается.)
Уильям Джоунз впервые высказывает идею, что такое сходство не может быть случайным и не может возникнуть в результате заимствования. А сходство, действительно, совершенно ошеломляющее. Вот, смотрите:

‘Новый’: в санскрите nava-, в латыни novus, в греческом νέος (неос; ну, тут мы звука в не видим, потому что греческому языку не повезло: в между гласными там не выживает, там его просто нет, там даже буквы для него нет; т. е. есть буква «дигамма», которая иногда, в некоторых диалектах, в древние времена…, но если мы берём классический греческий, то там уже никакой дигаммы нету, просто неос). В английском new — орфография очень старая, поэтому она нам показывает те времена, когда это w ещё произносилось.
Местоимение ‘ты’: в санскрите основа tva- или tu-, в латыни tū. В английском thou — это устаревшая форма, но она в письменных памятниках засвидетельствована и сейчас используется либо для архаизации, либо в религиозных текстах.
‘Два’: в санскрите основа dva- (дальше окончания двойственного числа), в латыни duo, в греческом δυο (дюо), у нас два (если в мужском роде) или две (если в женском роде), потому что двойственное число склоняется по разным склонениям. В санскрите оно тоже будет по разным склонениям склоняться в зависимости от рода (число, естественно, двойственное). Англ. two — тоже w видно по орфографии, когда-то оно произносилось.
Слово ‘брат’: в санскрите bhrātar-, в латыни frāter, в английском brother (в греческом φράτηρ (фратер) тоже есть, но это член рода, а не прямо родной брат). Ну, тут видно, что и русский тоже вполне в это вписывается.
А вот дальше русский немножко не вписывается.
‘Нести’: в санскрите bhar-, в латыни fero, в греческом φέρω, в английском bear (не то, которое ‘медведь’, а то от которого birthday образовано). Кстати, обратите внимание на соответствия согласных: где в санскрите bh — там в латыни f, и в греческом тоже φ (ф), а в английском b; где в греческом, латыни и в санскрите d, там в английском t; где в греческом, латыни и в санскрите t, там в английском то, что пишется через th, а читается в зависимости от позиции. В данном случае оно читается как ð.
Вот ‘отец’: в русском этого слова тоже нет, а в санскрите есть, в санскрите — pitar-, в латыни – pater. В греческом πατερ- (и дальше там будут окончания; я специально выбрала форму основы, а не форму именительного падежа, потому что буковка ε больше похожа на е, вам читать легче будет). В английском father — кстати, обратите внимание, что не только t превращается в th, но и p превращается в f – это первое (германское) передвижение согласных (а ещё бывает второе, немецкое).
‘‘идти’: скр. i-, лат. i-, греч. ει-
((наст. вр.: скр. ayāmi, лат. eo, греч. εἴμι)
‘Идти’ — везде i-, и в русском тоже и-, в греческом ει- – это потому, что глагольные корни умеют делать чередование гласных, и если мы возьмём настоящее время, то в санскрите будет ayāmi, в лат. eo (й между гласными не бывает в такой ситуации), греческое εἴμι – и мы видим здесь дифтонг ei.

Показатель именительного и винительного падежа (он одинаковый в среднем роде) во множественном числе везде -а — то есть слова типа сёла, озёра, дела —то, что будет среднего рода, будет заканчиваться на -а.
И понятно, что случайностей таких быть не может, и заимствований таких быть не может – кто будет заимствовать чередования в глагольной основе? Кто будет заимствовать идею, что средний род должен во множественном числе заканчиваться на -а? Вообще, почему слова должны быть какого-то рода? Особенно, если это неодушевлённые существительные. Английский без этого вполне обходится – и ничего, всем нормально. Но тут именно так. Причём одни и те же слова относятся к одному и тому же роду: если мы возьмём там какое-нибудь слово «дом», оно есть в русском, оно есть в латыни, оно есть в санскрите — и везде оно мужского рода и так называемого «о-склонения» (то есть «второго склонения»). Или, вернее, оно болтается между вторым склонением и так называемым «у-склонением» — в русском языке его сейчас нет, а раньше было. Если мы возьмём какое-нибудь слово «ночь», так она везде женского рода. Опять же можно поговорить о богах, которые какого-то рода, но обычно первичен именно язык, и если в языке соответствующее слово мужского рода, то бог будет мужчиной, а если женского, то бог будет, соответственно, женщиной. Ну, например, если вы читали Пратчетта, то, может быть, помните, что там Смерть мужского рода. Так вот, исконное германское существительное (которое мы в немецком знаем как Tod, в английском, соответственно, death) – оно мужского рода. Английский сейчас это утратил, в нём «смерть» никакого рода, но германские языки имеют «смерть» мужского рода. А в русском языке смерть женского рода, поэтому у нас это такая старуха с косой. Так что санскрит похож на европейские языки – и даже очень, причем в таких сущностных вещах, которые никто не будет заимствовать и которые не могут быть объяснены случайностью.
А вот, пожалуйста, санскрит похож на латынь, но без русского.

Вот слово ‘конь’: скр. aśvas и лат. equus (окончание -s для санскрита я написала условно, оно там будет чередоваться, поэтому в других местах я его выписывать не буду). Тут соответствие буква в букву просто! А у нас этого слова нет.
Какой-нибудь ‘царь’ — это основа rājan- в санскрите и rex в латыни (корень reg-, откуда regula ‘правило’, regio, род.пад. regionis ‘регион’, соответственно, ‘место где кто-то правит’, и так далее).
‘Мужчина’: vīra- в санскрите, vir в латыни.
«Змея» (от глагола ‘ползать’): sarpa- в санскрите, serpens в латыни.
«Нога»: в санскрите основа pad-, в латыни основа ped- (откуда велосипед, педаль, и другие заимствования).
А у нас всех этих корней просто нет. Так что пожалуйста, если приезжать санскритологу в Древний Рим, то там тоже вполне можно обнаружить кучу всего похожего.
В других случаях у нас эти слова есть, но немножко с другим фонетическим развитием.
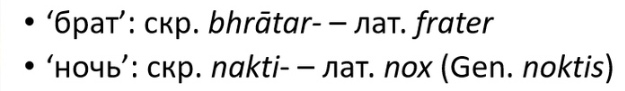
Вот брат, например: у нас р нету (а в санскрите есть: bhrātar).
Ночь, например: у нас этого kt не видно, а в латыни и санскрите оно видно.
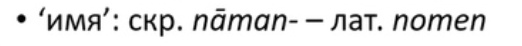
Имя — что у нас, у славян, случилось с началом этого слова, не знает никто (все просто тихо надеются, что корень тот же самый).
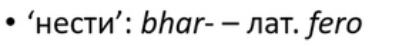
‘Нести’ — у нас изменилось значение, у нас этот корень означает ‘брать’.

Суть, глагол (как во фразе «эти многоугольники суть конгруэнтны»): у нас н не видно, а в латыни и санскрите видно.
Пожалуйста: можно сделать так, чтобы санскрит был похож на греческий.

Кстати, обратите внимание, что тут не только корни, и не только существительные, но и глагольные корни вполне находятся, глагольные окончания вполне находятся – их там достаточно много одинаковых. Приставки находятся прекрасные, и связанные с ними наречия. Перфект образуется одинаковым образом: то есть, надо удвоить первый согласный корня и добавить гласный е. В греческом так всё и останется, поэтому от γράφω (графо) мы видим γέγραφα (геграфа). Мы прямо это е видим (в последней строчке). А в санскрите е краткое превратилось в а (и о краткое тоже превратилось в а краткое), поэтому там е мы не видим – но зато мы видим палатализацию: будет не *какара, а чакара. Развитие ч из к по палатализации — такое же, как у нас. Поэтому чем-то санскрит больше похож на греческий, а чем-то больше похож, наоборот, на русский.
А можно найти такие примеры, чтобы русский был похож на латынь (больше, чем на санскрит).

Вот семя, а в латыни — sēmen, луна — и в латыни тоже lūna (и да, это не заимствование, хотя они такие одинаковые).
Секу – а в лат. seco. В санскрите этого корня, как и двух предыдущих, нет.
Пасу – а в латыни pasco. Ну, здесь, правда, -sc- — это суффикс, но видно, что корень pas- у этого глагола, и поэтому какой-нибудь pastor (там -t- и -or – это суффиксы, а pas- — корень) – это ‘тот, кто пасёт’.
Новый – novus, о и в русском, и в латыни, а в санскрите нава, через а (как я уже говорила, такое было развитие гласных).
Русское есть (бытийный глагол), в латыни est – а в санскрите asti. Кстати, связка, на которую кивал вышеупомянутый брахман-санскритолог, отсутствует в современном русском и отсутствует в санскрите (она не нужна, не обязательна), но в древнерусском она вполне была и довольно часто употреблялась (откуда мы, собственно, знаем все формы этого глагола).
И таких сходств, видимых невооруженным глазом, можно набрать достаточно много для любой пары языков индоевропейской семьи.
Это я вам показываю сходства, которые видно невооружённым глазом, — но для науки это не годится. Потому что сходство, как и красота, — в глазах смотрящего. Как известно, для многих русских все китайцы на одно лицо. С вьетнамцами. А для многих китайцев все русские на одно лицо. Оглядитесь вокруг, видно же, что все лица под копирку, правда? А в Московском метро есть две станции с одинаковыми названиями: «Водный стадион» и «Речной вокзал». Вот вы смеётесь, а многие путаются, потом звонят и говорят:
– Ой, а где тут такой-то автобус?
– А ты на какой станции?
Поэтому полагаться на то, что видно невооружённым глазом, наука не может. У каждого глаз свой и видит своё. Поэтому наука (любая наука, не только лингвистика) с самого начала своего существования тем и занимается, что вооружает глаз. Чтобы увидеть то, что невооружённым глазом не видно. Чтобы в том, что невооружённому глазу кажется каким-то хаосом или каким-то чудом, увидеть закономерность. Для этого наука вооружает глаз. Чем дальше, тем больше. И это хорошо, потому что многое становится видно – не как хаос и не как чудо, а как закономерность. Но это имеет и свою оборотную сторону: теперь, чтобы смотреть вооружённым глазом, надо долго тренироваться и учиться. Вот в докладе о ВИЧ и ВИЧ-диссидентах показали бинокулярный микроскоп (он же бинокуляр). Я в него смотреть не умею, меня не научили в детстве. Поэтому когда мне люди хотят показать какие-нибудь микроскопические красоты, я гляжу в этот бинокуляр и вижу какую-то белёсую муть. Но я не буду говорить, что «вы всё врёте», «ничего у вас там нет», «учёные скрывают»... Они ничего не скрывают, они показывают, просто я в бинокуляр смотреть не умею. Так что, если учёный вам что-то показывает, а вам не видно, то, может быть, вы просто не умеете смотреть в этот бинокуляр.
Итак, для науки нужен критерий, который будет получать результаты (похоже или непохоже, то же самое или не то же самое) независимо от того, кто на это будет смотреть. И способен ли этот кто-то считать, что все русские на одно лицо (или все китайцы) и так далее.
Этим критерием стали регулярные фонетические соответствия (= регулярные звуковые соответствия).

«Всякое фонетическое изменение, поскольку оно происходит механически, совершается по законам, не знающим исключений, т. е. направление фонетического изменения у всех членов языкового коллектива всегда одинаково, если не считать случая диалектного разделения, и все слова, заключающие подверженный изменению звук в одинаковых условиях, подчиняются ему безо всякого исключения» (На слайде вы видите портреты младограмматиков, с которых, собственно, это и пошло в такой формулировке).
И на самом деле, вы легко можете это увидеть — понаблюдайте за теми вашими знакомыми, которые не выговаривают, например, р. Вот не будет у вас такого знакомого, который в слове рак выговаривает р нормально, а в слове раб не выговаривает (или наоборот). Но вполне может найтись человек, который в слове речь выговаривает р’ нормальное, а в слове жрец не выговаривает, испытывает с этим какие-то затруднения. Потому что речь и жрец — это разные позиции, в одном случае начало слова, в другом случае – позиция после согласного шипящего. И тут бывает по-разному: перед ударением и после ударения, в начале слова и на конце слова, между гласными и т. д. – разные позиции. Но бывают позиции и морфологические, например, в приставке всё будет немножко не так, как в корне.
И это является критерием: если у нас имеются сходства, подкреплённые регулярными звуковыми соответствиями, то тогда мы можем сказать, что да — эти слова родственны. И, соответственно, если родственны такие слова, которые в любом языке есть (их заимствовать не надо, это так называемая «базисная лексика») то тогда можно говорить о родстве языков. Кстати говоря, когда я вам демонстрировала сходство санскрита с языками Европы, я обратила ваше внимание на регулярность звуковых соответствий. Когда в санскрите bh, то в русском б, в греческом f и так далее. Это уже вполне критерий, и он не зависит от того, кто на это смотрит. Просто берёшь базисную лексику, которую не надо заимствовать, и смотришь — есть там регулярные соответствия или нет. Если есть, значит да, языки родственные.
Почему же возникает впечатление именно о сходстве русского с санскритом? Потому что у балто-славянских языков с индо-иранскими довольно много общих инноваций.

Одну инновацию я уже упоминала, в русском печёт – в санскрите pacati, к переходит в ч, а в латыни эта форма выглядит как coquit. Огубленного звука kw ни балто-славянский, ни индо-иранский не сохраняют, у них к вместо него. И палатализации здесь в латыни нет (то есть kw не будет палатализоваться).
Живёт: в санскрите jīvati, в латыни – vīvit. Ну, это был такой странный звук в начале этого слова, и в русском, и в санскрите он дал довольно похожие рефлексы – ж и дж. А в латыни он дал v, и поэтому получается уже не так похоже.
Русское четверо очень похоже на санскритское четыре catvāra- (дальше будет окончание). В латыни quattuor, опять же kw, которое не палатализуется.

Русское слыть, санскритское śru-, а в латыни вместо вот этого с или щ, будет к (по этому признаку языки делятся на языки «сатем» и языки «кентум»: балто-славянский и индо-иранский – это языки «сатем», а латынь, греческий и германские языки – это языки «кентум», поэтому у них будет k, а у нас будет с, если в русском, щ, если в санскрите, с в иранском и так далее).
Точно так же острый (санскр. aśr-, но лат. ācer), точно так же весь (которая в выражении «по городам и весям», означает ‘селение’): у нас весь через с, в санскрите víś через ś (щ), а в латыни vīcus через с (читается к).
Но если вы думаете, что русский язык – это язык, самый похожий на санскрит, то это не так. Самый похожий на санскрит язык – это литовский.

Вот ‘кто’ в литовском kas – и в санскрите kas (дальше с этим -as будет происходит удивительное, потому что когда слова становятся рядом, то в санскрите концы и начала могут довольно сильно меняться).
В литовском kataras (но это, правда, диалектная форма, литературная – katras) – в санскрите kataras, значит ‘который’, но у нас там о, а у них – а.
Sūnus в литовском, sūnus в санскрите – это сын. У нас ы, а у них прямо долгое ū в неизменном виде.
Naktis в литовском, naktis в санскрите – это ночь соответственно.
Vyras : игрек в литовском – это долгое i, и в санскрите тоже долгое i, vīras – это ‘мужчина’.
Но значит ли это, что, выучив литовский, вы будете без проблем понимать санскрит? Конечно, нет. Даже если вы выучите хинди — это вам поможет с пониманием санскрита не больше, чем знание современного русского помогает читать «Слово о полку Игореве».
Поэтому, если хотите понимать санскрит — учите санскрит!
Источник: Стенограмма доклада
Ранее по этой теме (видео):
"Какой же русский не понимает санскрита?" (Видео)
https://cont.ws/@stopfreak/104...
"Видеотека. Какой же русский не понимает санскрита? Светлана Бурлак. Ученые против мифов 7-11 (Видео)"
https://cont.ws/@fenol/1046050











Оценили 27 человек
57 кармы