

Чарльз Э. Торнтон, студент, член IEEE, Марк А. Кози, Р. Майкл Бюрер, Член IEEE, Энтони Ф. Мартон, старший член IEEE, и Келли Д. Шербонди, член IEEEК.
Э. Торнтон, М. А. Кози и Р. М. Бюрер работают в Wireless@VT, департамент ЕЭК, Блэксбург, Вирджиния, США. Email {cthorn14, buehrer}@vt.edu А. Ф. Мартон и К. Д. Шербонди работают в научно-исследовательской лаборатории армии США в Адельфи, штат Мэриленд, США.
Аннотация — В данной работе рассматривается динамическое некооперативное сосуществование когнитивного импульсного радара и близлежащих систем связи путём применения нелинейной аппроксимации функции ценности с помощью глубокого обучения с подкреплением (Deep Reinforcement Learning) для разработки политики оптимальной работы радара.
Радар учится изменять полосу пропускания (фильтр) и основную частоту своих сигналов с линейной частотной модуляцией (LFM), чтобы уменьшить помехи других систем для улучшения характеристик обнаружения целей, а также использовать другие доступные полосы частот для достижения точного разрешения диапазона. Мы продемонстрируем, что этот подход, основанный на алгоритме глубокого Q-обучения (DQL), повышает некоторые показатели производительности радара более эффективно, чем итерация политики или подходы Sense-and-avoid (SAA) в нескольких реалистичных средах сосуществования.
Подход, основанный на DQL, также расширяется за счёт включения двойного Q-обучения рекуррентной нейронной сети для формирования двойной глубокой рекуррентной Q-сети (DDRQN), которая обеспечивает благоприятную производительность и стабильность по сравнению с DQL и итерацией политик. Практичность предложенной схемы продемонстрирована на примере экспериментов, проведённых на системе с прототипом программно-определяемого радара (SDRadar). Экспериментальные результаты показывают, что предложенный подход Deep RL значительно улучшает характеристики радиолокационного обнаружения в перегруженных спектральных средах по сравнению с итерацией политики и SAA.
Индексные термины — Глубокое обучение с подкреплением (Deep Reinforcement Learning, Deep RL), когнитивный радар, Марковский процесс принятия решений, распределение спектра.
I. ВВЕДЕНИЕ
С появлением массового внедрения сотовой технологии пятого поколения (5G) беспроводной трафик становится более тяжёлым и концентрированным , чем когда-либо прежде, и все признаки указывают на продолжение роста [1]. Кроме того, в последние годы резко возросло число критически важных применений радиолокационных систем как для государственных, так и для коммерческих целей. Радиолокационные и коммуникационные системы требуют доступа к значительному участку полос частот ниже 6 ГГц, которые планируется использовать в качестве основного частотного диапазона для систем 5G [2]. Кроме того, применение радаров малой дальности также требует доступа к спектру в миллиметровом радиодиапазоне, который также предлагаются для использования в 5G.
Таким образом, интеллектуальный доступ к спектру радиочастот будет важным конструктивным соображением для радиолокационных систем будущего. Поскольку полосы частот выше 1 ГГц традиционно статически распределяются для использования радиолокаторами, подавляющее большинство современных радиолокационных систем используют большие участки выделенного спектра фиксированным образом, что приводит к потенциальным трудностям при принятии политик распределения спектра [3].
Эффективное совместное использование спектра с точки зрения радиолокации требует надёжных системы, способные принимать оптимальные решения в гетерогенной электромагнитной среде [4]. Когнитивный радар, с разноплановой концепцией, впервые предложенной Хайкин в [5], относится к радиолокационным системам, использующим обратную информационную связь между передатчиком и приёмником, чтобы оптимизировать интересующие параметры. Например, радар может стремиться к максимизации своей производительности обнаружения, или свести к минимуму взаимные помехи с другими потребителями спектра в зависимости от статистической информации о помехах в канале [6].
Когнитивный радар обладает возможностью удовлетворения строгих спектральных ограничений с помощью комбинации адаптивных, прогностических и традиционных методов радиолокационной обработки или оптимизации формы волны [7]. В то время как полностью самодостаточная радиолокационная система остаётся недостижимой целью в развитии систем, основанных на применении данных подходов к радиолокационным системам следующего поколения, этот метод может значительно повысить производительность.
Область применения когнитивного радара обширна, и современные исследования обычно можно разделить на два основных направления. Первое фокусируется на повышении производительности физического уровня и включает в себя такие методы, как оптимизация формы сигнала передачи [8], когнитивное формирование луча [9] и управление ресурсами [10]. Последний фокусируется на возможностях распределения спектра и использует теоретико-игровые подходы [11], спектрально-наполненный дизайн формы волны [12] и методы быстрого реагирования Sense-and-avoid (SAA) — чутко-и-настороженно [13] для сглаживания помех. Однако огромное количество получаемых и обрабатываемых РЛС данных, а также простота использования информации о состоянии канала (CSI) за счёт совместного расположения передатчика и приёмника, делает задачу управления РЛС естественным кандидатом на алгоритмы глубокого обучения с подтверждением (Deep RL) [14].
В этой работе предлагается подход глубокого подкрепления обучения (Deep RL), в частности, аппроксимация функции ценности с использованием глубокой Q-сети (DQN), чтобы улучшить возможности разделённого спектра когнитивного радара за пределами существующих подходов. Это исследование расширяет подход, описанный в [15], который моделирует выбор формы волны когнитивного радара как марковский процесс принятия решений (MDP), который представляет собой математическое представление последовательного процесса принятия решений [16]. Оптимальная политика находится с помощью алгоритма динамического программирования обучения с подкреплением (RL) , называемого итерацией политики, и, как показано, сглаживает взаимные помехи между радаром и единой системой связи.
К сожалению, высокая размерность итерационного подхода к политике ограничивает число состояний, которые может рассматривать радар, что приводит к ограниченной модели окружающей среды. Точно так же ограничения на количество действий, которые может предпринять радар, ограничивают способность агента эффективно использовать весь имеющийся спектр. Предложенный здесь подход Deep RL представляет собой вычислительно осуществимую схему для решения этих проблем.
Кроме того, методы Deep RL, представленные здесь, позволяют в режиме реального времени обновлять изученное поведение, так что радар может продолжать обучение в случае нестационарного использования в окружающей среде.
Аппроксимация нелинейных функций с использованием моделей глубокого обучения может позволить RL масштабироваться до задач принятия решений, которые ранее были неразрешимыми [17]. В Deep RL время вычислений на обновление не растёт вместе с числом обучающих состояний, как это происходит при динамических подходах программирования, таких как итерация политики. Ещё одним ранее показанным ограничением итерационного подхода политики является плохая производительность обобщения при наличии ранее неизвестных состояний интерференции. В модели [15] при наличии ранее ненаблюдаемого состояния РЛС принимает действие по умолчанию в качестве модели перехода состояния, что для этого случая пока ещё не определено. В качестве альтернативы Deep RL позволяет радару предпринимать более обоснованные действия, основанные на расчётном значении функции.
Тем не менее, при применении Deep RL к когнитивному радару необходимо решить некоторые доменные проблемы. Радиолокационные системы должны извлекать конкретную информацию о цели, которая в значительной степени зависит от рабочей частоты, в дополнение к характеристикам цели, которые могут быть априори неизвестны. Кроме того, радар особенно восприимчив к помехам из-за двухмерных потерь при распространении (излучении?). Многие предыдущие работы в области когнитивного радара адресованы конкретной установке или приложению.
Тем не менее, когнитивный радар стремится обеспечить надёжную работу в широком диапазоне настроек. Таким образом в нашем подходе рассматривается потребность в общем глубоком RL фреймворке, который может обращаться (использовать) к различным функциям обнаружения и отслеживания.
Другая конкретная задача - разработка практической схемы для систем реального времени. В то время как Deep RL, как известно , очень эффективен в синтетических средах, таких как видеоигры, его применение усложняется, когда схема должна быть синергетической с другими процессами, такими как задачи обработки сигналов, выполняемые радарами. С помощью моделирования и экспериментов мы демонстрируем, что наша схема реализуема, а также выделяем ключевые конструктивные соображения, такие как ограничение адаптации формы сигнала внутри ИПЦ и влияние нестационарных сред.
A. Значимость этой работы
Эта статья значительно расширяет предварительную работу [18], в которой представлена базовая версия используемого здесь подхода DQN и его имитационная работа при наличии простых сценариев интерференции. В этой работе мы вносим следующие ключевые вклады:
• Мы приводим полное описание модели Deep RL, демонстрирующей эффективность когнитивного радара в сложных и реалистичных сценариях сосуществования спектров, и детальное сравнение как с подходом итерации политики MDP, описанным в [15], так и с наивной схемой SAA, чтобы широко продемонстрировать преимущество Deep RL в сценариях сосуществования когнитивных радаров.
• Мы представляем расширение подхода Deep RL , который использует двойное Q-обучение и рекуррентную архитектуру LSTM для стабилизации процесса обучения и изучения расширенных временных корреляций, когда интерференция нарушает свойство Маркова. Эта архитектура известна как Двойная глубокая рекуррентная Q-сеть (DDRQN).
• Мы демонстрируем, насколько глубоко RL может быть практически применён для повышения эффективности радиолокационного обнаружения по сравнению с другими когнитивными методами, с помощью экспериментов, выполненных на аппаратной реализации прототипа радиолокационной системы.
• Мы отмечаем, что подход Deep RL демонстрирует несколько улучшений по сравнению с итерацией политик. Во-первых, явные модели перехода и возврата не должны наблюдаться заранее. Это позволяет быстрее собирать или обрабатывать больше информации о состоянии канала.
Кроме того, радар более эффективно адаптируется в новых средах, поскольку радар может выполнять он-лайн обучение и обновлять свои приоритеты при передаче в режиме реального времени. Наконец, радар разрабатывает более эффективные паттерны поведения, которые приводят к меньшим ошибкам в обработке данных доплеровского диапазона, чем другие когнитивные методы.
B. Организация
Эта статья построена следующим образом. В разделе II рассматривается предыдущая работа по когнитивному радару. В разделе III описываются формулировка MDP, глубокая архитектура RL и соображения по моделированию. В разделе IV представлены результаты моделирования и сравнение показателей производительности с другими схемами. В разделе V обсуждается аппаратная реализация подхода DQN для программно-определяемого радара (SDRadar) и приводятся результаты экспериментов. В разделе VI содержатся заключительные замечания.
II. СОПУТСТВУЮЩИЕ РАБОТЫ
Когнитивные радиолокационные исследования включают в себя как ориентированные на производительность подходы, так и методы, обеспечивающие разделение спектра. Исследования, направленные на повышение производительности, включают в себя повышение производительности физического уровня за счёт оптимизации формы сигнала передачи через контур обратной связи [8].
Это позволяет использовать форму сигнала передачи для использования особенностей окружающей среды для более точной оценки цели. Например, общая структура байесовского многоуровневого подхода к отслеживанию целей представлена в работе [19]. Управление радиолокационными ресурсами (РРМ) является ещё одной важной темой исследований
для когнитивных радиолокационных систем, ориентированных на производительность [10]. RRM используется для создания приоритетного планирования для внутренних процессов, которые конкурируют за ограниченные физические ресурсы. Дополнительным когнитивным методом, который может быть использован для повышения эффективности обнаружения, является классификация целей по изображениям РЛС с обратной синтетической апертурой (ISAR) [20], при которой информация извлекается из двухмерных изображений высокого разрешения для различения различных целей.
В рамках исследований распределения спектра для когнитивного радара литература может быть разделена на подходы сосуществования и сотрудничества [21]. Сосуществование схем монитора, спектра и регулировки системы поведения для уменьшения взаимных коллизий между пользователями возможно в кооперативных схемах с подписью кода, чтобы оптимизировать поведение нескольких пользователей.
В некоторых кооперативных схемах совместно оптимизировано использование радарного коммуникационного узла [22], в то время как другие пытаются рассматривать спектральный сценарий как кооперативную игру [11], который требует от пользователей делать компромиссы для совместной оптимизации. Однако кооперативные схемы часто являются дорогостоящими в реализации и требуют тщательного планирования.
Квинтэссенцией подхода сосуществования является динамический доступ к спектру (Dynamics Spectrum Access, DSA), в котором пользователям присваивается статус первичного пользователя (PU) или вторичного пользователя (SU), и SU может получить доступ к спектру с задержкой по времени, только когда PU неактивен [23]. В работе [24] авторы разработали сжатую схему зондирования для снижения нагрузки спектрального зондирования на цифровые сигнальные процессоры и использовали статистические методы для оценки поведения первичного пользователя (ПУ) для управления радиолокационными передачами. В отличие от планирования пользовательских передач, методы SAA, которые адаптируют время и частоту локации радиолокационных импульсов, были использованы для реактивного избежания помех [13], [4]. Однако SAA предполагает, что поведение интерференции является стационарным между временными отметками и может быть неэффективным в сценариях, когда время когерентности канала очень мало.
Другим методом сосуществования является введение спектральных насечек в передающую форму сигнала для ослабления помех [25]. Однако формы сигналов ограничены полосой пропускания и возникают за счет увеличения боковых лепестков диапазона в когерентно обрабатываемых данных [12]. Для разработки более интеллектуальных радиолокационных систем многие работы по применению когнитивных радиолокационных адаптивных методов, основаны на цикле действия восприятия (PAC) [7], [13], который считается фундаментальным аспектом познания животных. PAC включает в себя круговой поток информации для направления агента к определённой цели [26].
Эта структура может быть использована для моделирования работы когнитивного радара, который должен получить некоторую информацию о своей среде, действовать логически и ждать обратной связи, которая затем подаётся обратно в передатчик. Однако эти системы должны ограничивать обработку время для выполнения строгих требований к срокам. Таким образом, статистические подходы и подходы к машинному обучению оправданы своей способностью обрабатывать данные либо последовательно, либо пакетами, в зависимости от области применения.
Предыдущие приложения машинного обучения для когнитивных радиолокационных систем были сосредоточены на оптимизации высокоуровневых систем слежения за целями [27], [28], оптимизации порога обнаружения целей [29] и сетевой ассоциации для совместного проектирования радиолокации и связи [30]. Однако использование глубокого обучения для управления выбором формы сигнала в реальном времени остаётся относительно неисследованным в литературе, где многочисленные недавние достижения в области RL могут быть использованы для совместного рассмотрения спектральной эффективности и характеристик радара.
Было продемонстрировано, что задачи, точно смоделированные как MDP, могут быть эффективно решены такими архитектурами, как Deep-Q Network (DQN) или рекуррентная свёрточная нейронная сеть (RCNNs) [17]. В частности, было показано, что архитектура DQN обеспечивает управление на человеческом уровнем в среде, моделируемой MDP, с помощью формы Q-обучения и стохастического градиентного спуска (SGD) для обновления весов нескольких скрытых слоёв сети в [31]. Однако эффективность такого подхода в значительной степени зависит от качества оценки окружающей среды самой РЛС. В реальных приложениях модель окружающей среды может привести к частичным или неполным наблюдениям, что создает дополнительные проблемы.
Недавно было предложено расширить DQN, чтобы помочь при изучении последовательных данных устраните предвзятость оценки и расставьте приоритеты в отношении важного опыта с поощрением эмпирической эффективности [32], [33]. В данной работе исследуются необходимые соображения при реализации этих идей в новой прототипной системе когнитивного радара.
III. MОДЕЛЬ СИСТЕМЫ И ПОДХОД К ГЛУБОКОМУ ФОРСИРОВАННОМУ ОБУЧЕНИЮ
Эта когнитивная радиолокационная система предполагает модель радиолокационной среды в виде MDP и, следовательно, зависимость между соседними временными метками, обусловленную свойством Маркова. Однако мы также тестируем этот подход в реалистичных сценариях, поэтому, даже если это предположение не выполняется, мы считаем, что этот подход эффективен, и проблему можно считать почти марковской. Кроме того, рекуррентная архитектура используется в предлагаемом DDRQN для изучения интерференции с расширенной временной корреляцией. Теперь мы переходим к описанию радиолокационной обстановки и формулировке MDP, за которой следуют подробности DQN архитектуры, используемые для выполнения Deep RL.
A. Окружающая среда сосуществования и формулирование MDP
Рассмотрим радиолокационную среду, состоящую из одной точечной цели, которая отслеживается радаром в течение эпизода, состоящего из многих временных засечек, где каждый временной шаг соответствует радиолокационному импульсу. Цель имеет некоторую случайно определённую траекторию для каждого отдельного эпизода. Среда электромагнитного поля - это общий канал, разделённый на N подканалов одинакового размера. В этой среде установлена система связи, которая способна работать в одном или нескольких поддиапазонах одновременно, и может создавать помехи для радара.
Радиолокационная система является моностатической и стационарной и работает используя чирк-форму (chirp) сигнала линейной частотной модуляции (LFM) в соответствии с продуктом временной полосы пропускания*.
* Произведение временной полосы пропускания задается T BP = T ( fh i − f lo) где T - это длина импульса и fh i − f lo это частота, охватываемая формой волны чирпа.
Потери, вызванные атмосферными воздействиями или беспорядком, считаются незначительными. Пример радиолокационной сцены показан на рис. 1.

Оранжевые круги представляют возможные позиции цели, а стрелка представляет траекторию цели. Целевое положение - непрерывная переменная, но мы используем квантованные значения для поддержания гибкости. MDP является хорошо изученной математической основой для последовательного принятия решений в условиях неопределенности [16]. Модель задаётся набором элементов (S, A, T, R, γ). Структура состоит из состояний, действий, вероятностей перехода, функции вознаграждения и коэффициента дисконтирования. Состояние s ∈ S является уникальным набором важной информации в моделируемой задаче.
Здесь состояние - это вектор, который включает в себя положение цели x ∈ X = {x1, ..., xP}, скорость цели v ∈ V = {v1, ..., vV}, и помехи, вызванные системой связи θ ∈ Θ= {θ1, ...,θM},где P - количество позиционных состояний, V - количество скоростных состояний, а M - количество уникальных интерференционных состояний.
Каждое состояние интерференции θi ∈ Θ выражается в виде длины N вектора двоичных значений, в котором 1 соответствует занятому подканалу, а 0 - доступности. Например, в случае N = 5 поддиапазонов θ = [1, 1, 1, 0, 0] соответствует первым трём используемым подканалам, а остальные подканалы доступны для использования радаром.
При N поддиапазонах общее число уникальных интерференционных состояний тогда равно M = 2N Таким образом, общее число состояний составляет Ns = P ×V ×2N, которое растёт экспоненциально по мере увеличения числа поддиапазонов, ограничивая практически нашу дискретизацию канала.
Пространство действия радара А состоит из передач в любой группе смежных поддиапазонов. Аналогично состоянию интерференции θ, каждое радиолокационное действие аi ∈ A = {a1, ..., aNa} формулируется как вектор длины N двоичных значений, в котором 1 соответствует наличию чирп-сигнала радара, а 0 - отсутствию радиолокационной активности. Поскольку радар ограничен занятием смежных подканалов, число действий тогда Na=N (N +1)/2.
Функция вероятности перехода T (s, a, s′) : S×A×S →[0, 1] - это вероятность достижения состояния s′ приняв меры некоторое время назад в состоянии s. Структура MDP предполагает, что Марковское свойство справедливо для окружающей среды, и поэтому рассматриваются только одноходовые переходы. Однако это предположение будет ослаблено при глубоком подходе RL. Функция вознаграждения R(s, a, s′) : S × A × S → R задаёт числовое значение, определяющее предпочтение агента для выполнения какого-либо действия находясь в определённом состоянии, и определяется системным планировщиком. Уникальное сочетание функций вознаграждения и перехода характеризует модель MDP.
** Поскольку радар ограничивается передачами в смежных поддиапазонах, число возможных передач всегда будет треугольным числом, что даёт результат N (N + 1)/2.
Наконец, коэффициент дисконтирования γ ∈ [0, 1] - это весовой коэффициент, определяющий предпочтение радара краткосрочным (γ ≈ 0) или долгосрочным (γ ≈ 1) вознаграждениям. Цель RL - максимизировать дисконтированное вознаграждение, задаваемое взвешенной суммой вознаграждений (1)
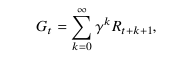
где Rт +к+1 это награда в момент времени t + k + 1. Выбор функции вознаграждения, соответствующей идеальному взаимодействию с окружающей средой, является критическим аспектом любого подхода RL, поэтому здесь следует проявить осторожность. Радар должен использовать наибольший доступный спектр для получения точного расчёта диапазона. Кроме того, мы хотим минимизировать помехи для других систем и улучшить возможности обнаружения целей, поэтому случаи, когда радар занимает полосы частот одновременно с системами связи, должны быть предотвращены.
Предыдущая работа показала, что вознаграждения основаны на взвешенном сочетание SINR и полосы пропускания служит для повышения возможностей обнаружения целей РЛС [15].
Этот тип функции вознаграждения имеет вид (2)
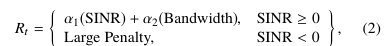
где α1 и α2 это аргументы. Поскольку SINR соответствует выступу цели в данных доплеровской обработки дальности, а большая полоса пропускания связана с более тонким разрешением дальности, этот компромисс интуитивно понятен с точки зрения характеристик радара. Однако надёжные измерения SINR требуют знания дальности цели и предположений о свойствах рассеяния. Далее, в зависимости от значений α1 и α2, радар может получить достаточно высокий приоритет используя весь канал, что может не способствовать сценариям сосуществования. Чтобы способствовать как предотвращению помех, так и использованию полосы пропускания для совместного использования спектра, эта формулировка вместо этого использует функцию вознаграждения, основанную на упущенных возможностях и столкновениях.
Определение 1. Пусть число столкновений Nc соответствует количеству подканалов, используемых как радаром , так и системой связи,

где 1 {·} - это двоичная индикаторная функция и обозначение at,i соответствует ith - элемент действия, совершенного в момент времени t.
Определение 2. Пусть число упущенных возможностей Nmo соответствует разнице между наибольшей группой смежных подканалов, не используемых другими системами4, а*t, где а - число тех подканалов, которые фактически выбирает радар,
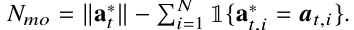
Функция вознаграждения радара R t∈ [0, 1] тогда может быть выражается как (3)
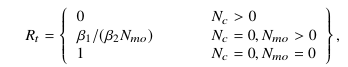
где 0 ≤ β1< β2 это параметры, которые определяют предпочтение радара для предотвращения помех относительно использования доступной полосы пропускания. Большие значения β1/β2 подчеркивают избегание помех, так как радар может достичь близкого к максимальному вознаграждения, несмотря на Nmo > 0. Альтернативно небольшой β1/β2 поощряет радар пытаться использовать полный доступный канал, когда это возможно, поскольку упущенные возможности приближают вознаграждение к 0. Выбор параметров вознаграждения в значительной степени зависит от приложения, поскольку разрешение по дальности и цели обнаружения целей будут диктовать предпочтения радара.
Эта функция вознаграждения оказывается эффективной, так как радар быстро узнает, что столкновение с радиочастотными помехами (RFI) дает минимальное вознаграждение. Таким образом, радар научится избегать действий, которые регулярно приводят к столкновениям. Чтобы получить максимально возможную награду, радар должен использовать наибольшее количество доступных смежных полос, что стимулирует использование доступного спектра. Далее, Nc и Nmo легко вычисляются на каждом временном шаге и ограничены по Nc≤ N и Nmo≤N−1 соответственно, способствуя стабильному процессу обучения и познаваемой связи между состояниями и действиями.
Цель MDP состоит в том, чтобы изучить отображение между состояниями и распределение вероятностей по действиям, известное как политика π. Оптимальная политика, которая даёт наибольшие ожидаемые результаты с урезанным вознаграждением обозначается через π∗..
Теперь мы опишем, как оптимальная политика может быть найдена итеративно с использованием подхода динамического программирования, известного как итерация политик и более практически аппроксимируемого с помощью нашего подхода Deep RL.
*** На практике радар может вычислять столкновения, оценивая SINR и обозначая столкновение как событие (SI N R < Γ). Обратите внимание, что для явного значения из SINR не требуется вычислять вознаграждение, как в (2).
**** На практике а*t может быть рассчитан используя пороговый детектор энергии.
B. Итерационный подход к политикам
Теперь мы кратко опишем итерационный подход политики в том виде, в каком он был реализован в работе [15] и будет использоваться в качестве базовой линии для сравнения с подходом Deep RL. Этот метод включает в себя оценку T (s, a, s′) через повторный опыт, за которым следует хорошо известный алгоритм итерации политики.
Итерация политик - это метод динамического программирования, выполняемый путем
запуска произвольной политики πo и итеративно выполнять два шага - оценку политики и улучшение политики. Во время оценки политики функция ценности Vπ(s), который описывает полезность пребывания в состоянии s при действии на политику π равна (4)

Затем улучшение политики использует Vπ(s) чтобы выбрать действие a так, что ожидаемая полезность следующего состояния s′ проявляется максимально. Этот процесс создаёт новую политику, π′ с помощью функция обновлённого значения Vπ′ что гарантированно будет больше чем или равно Vπ согласно теореме об улучшении политики [34].
Затем этот процесс повторяется до тех пор, пока мы не получим стабильное решение.
V∗(s) дано (5)
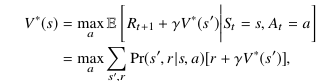
из которого мы берем (6)
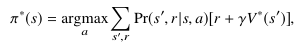
быть оптимальной политикой.*****
На практике условие остановки используется для завершения алгоритма, как только изменения становятся очень малыми.
Итерация политики будет сходиться к V∗(s) в конечном времени [34], но учитывая большие и часто разреженные, T (s, a, s′) и R(s, a, s′) матрицы, необходимые для выполнения вычислений, этот подход не является вычислительно выполнимым для больших пространств состояний-действий. Далее, чтобы вычислить π∗ радар должен уже иметь точную модель динамики перехода и вознаграждения, построенную на повторном опыте, который может занять много итераций и затруднить чувствительные ко времени приложения радара, такие как отслеживание цели. Наконец, однажды взятая π∗ при использовании этого подхода производительность радара фиксируется до тех пор, пока алгоритм не будет запущен снова. Для более практического подхода, когда динамика окружающей среды неизвестна, мы обращаемся к аппроксимации функций с помощью Deep RL.
C. Подход к Deep RL
Предлагаемый подход к Deep RL когнитивного радара основан на Deep Q-learning (DQL), алгоритме, который пытается найти приближенное решение MDP путём непосредственного изучения функции значений состояния-действия Q(s, a), которая сопоставляет пары состояний-действий с вознаграждениями [34]. Q(s, a) аналогична по своей природе функции значения состояния V(s) выше и выражается (7)
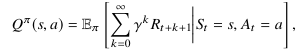
что соответствует ожидаемой полезности действия а в состоянии s во время следования π. Оптимальная функция Q, Q∗(s, a) тогда (8)
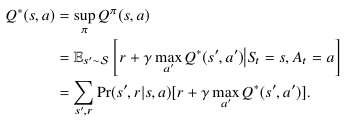
***** Функция оптимального значения гарантированно уникальна, но может быть несколько оптимальных политик.
DQL аппроксимирует Q∗(s, a) непосредственно, без рассмотрения всей политики. Это делается с помощью обновления градиента с помощью алгоритма обратного распространения для обновления весов нейронной сети на основе опыта радара. SGD оценивает градиент функции и обновляет веса, wt, на основе на одном случайно выбранном образце zt.
Общая форма из обновления SGD является
(9) wt+1 = wt − αt ▽w L(zt , wt ),
где αt это размер шага или скорость обучения, ▽w соответствует градиенту по отношению к весовому вектору w, а L (·) - функция потерь [35]. Для повышения точности оценки градиента
мы используем метод под названием experience replay [31]. На каждом временном шаге t радар совершает переход
(10) φt = (st , at , rt+1, st+1 ),
который затем хранится в буфере памяти М с большой, но фиксированной ёмкостью. Пакет равномерно дискретизированных переходов используется для выполнения обучающих обновлений. Этот метод направлен на получение некоррелированных выборок, которые улучшают оценку градиента, поскольку сильно коррелированные обновления нарушают присущее алгоритму SGD предположение i.i.d. Память воспроизведения также позволяет радару запоминать редкие, но потенциально важные события, произошедшие много временных шагов назад.
Аппроксимация функции значения с помощью нейронных сетей часто неустойчива из-за быстрой флуктуации оценок Q(s, a). Чтобы бороться с нестабильностью, DQNs используют целевую сеть для сглаживания процесса обучения [31]. В этом подходе целевая
сеть используется для хранения весов, которые используются для выбора наилучшего действия, обозначаемого вектором w′. Цель веса сети заморожены для T(target) временные шаги, в то время как отдельная политическая сеть с весовым вектором w реагирует на каждое наблюдаемое состояние. После T(target) шаги завершены, и веса целевой сети корректируются w ′ ← w. Это позволяет сети политики вычислять ошибки, не используя свои собственные оценки быстрых флуктуаций значений добротности для выбора форм сигналов.
Функция потерь, используемая для выполнения обучения, основана на стандартном обновлении временных разностей. Говорят, что эти две сети являются медленно обновляющейся целевой сетью с вектором веса w′, и сеть политики, которая обновляется каждый временной шаг, с вектором веса w. На каждой итерации i мы нарисуйте n приблизительно i.i.d. выборок из буфера памяти {φ i }i ∈M и сформируйте цель (11)

где обозначение Q(s, a; w ′i) соответствует текущему значению Q, оцениваемому замороженной целевой сетью с вектором веса w ′i. Функция потерь на каждом шаге i тогда (12)

где Q(si , ai ; wi ) соответствует аппроксимированному Q-значению политической сети, основанному на самом последнем опыте, и ожидание аппроксимируется с использованием n образцов из памяти. Обновления SGD могут быть выполнены с использованием градиента (12). Для дальнейшего анализа функции потерь мы можем применить декомпозицию смещения-дисперсии (13)
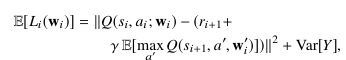
где первый член - это усреднённая ошибка Беллмана в квадрате (MBSE), общая мера расстояния между расчётной и истинной значений функции [34]. Далее мы отметим что дисперсия целевых показателей Y зависит от w ′i но не wi , что позволяет нам игнорировать дисперсионный член. Таким образом, минимизация (12) близка к нахождению минимума MSBE. Без использования целевой сети член дисперсии в (13) зависит от wi и минимизация (12) может расходиться с минимизацией MSBE [36]. Таким образом, как целевая сеть, так и воспроизведение опыта являются важными инструментами стабильности, которые могут быть теоретически обоснованы.
DQN, используемый для экспериментов в этой статье, построен на Python с использованием библиотеки TensorFlow [37]. Архитектура сети состоит из входного слоя, трех полностью соединенных скрытых слоев и выходного слоя. В то время как некоторые реализации вводят в сеть несколько предыдущих состояний, мы вводим только одно состояние, так как рассматриваемые сценарии интерференции часто являются стохастическими. На выходе каждого слоя применяются функции активации выпрямленного линейного блока (ReLU).
Конкретные варианты гиперпараметров, используемые как для архитектуры нейронной сети, так и для сцены радара, указаны в разделе IV.
Поскольку DQN состоит из многих весов, которые должны быть изучены непосредственно из опыта, мы используем автономное обучение или период исследования, чтобы разработать начальное приближение Q(s, a). В течение этой фазы радар выбирает действия с одинаковой вероятностью, наблюдает связанные φ(st , at , rt+1, st+1 ) переход, и обновляет буфер памяти, используемый для выполнения градиентных обновлений. В критическом приложении радар, вероятно, будет имитировать выполнение каждого действия, чтобы избежать плохой производительности, связанной со случайным исследованием.
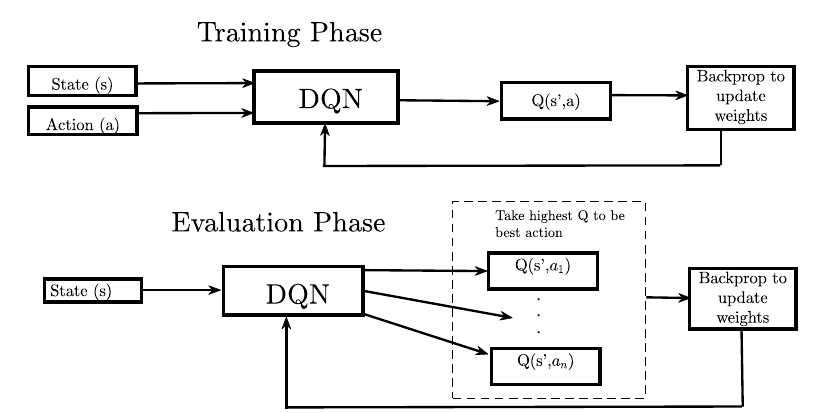
Радар входит в фазу онлайн-оценки, где на каждом шаге действия At= argmaxaQ(s, a) взят. Переходы по-прежнему сохраняются в буфере памяти и используются для обновления весов сети, позволяя адаптироваться в нестационарных средах или продолжать обучение, если опыт, накопленный на этапе исследования, был недостаточен для изучения окружающей среды. Этапы обучения и оценки представлены на рис. 2.
Глубокое Q-обучение имеет ряд важных теоретических преимуществ по сравнению с подходом итерации политики. Прежде всего, явные модели перехода и вознаграждения не являются необходимыми, и радиолокационное поведение может быть изучено на основе любого имеющегося опыта. Кроме того, уменьшенная размерность задачи позволяет рассматривать большие пространства состояний-действий, увеличивая прогностическую мощность радара в сценариях помех с расширенными временными зависимостями. Наконец, радар способен продолжать обновлять свои убеждения во время оценки, что выгодно в случаях динамической среды или недостаточное время для тренировок. Однако, поскольку модели перехода и вознаграждения недоступны, DQN сильно зависит от качества наблюдаемых переходов и связанных с ними оценок. Поскольку сценарии сосуществования часто являются динамическими, а зондирование спектра часто дает шумные измерения, мы представляем расширение DQN в следующем разделе.
D. Двойные глубокие рекуррентные Q-Сети
Модель DQN в значительной степени зависит от качества наблюдений и оценок для точной аппроксимации функций. Поскольку реальные наблюдения часто шумны или ненадежны, мы объединяем два важных расширения для глубокого Q-обучения в этом разделе для повышения производительности для домена совместного использования спектра. Первый метод - это использование двойного DQN (DDQN), который смягчает смещение оценок в процессе обучения [33]. Поскольку функция потерь в (12) предполагает принятие максимума над оценочными значениями, подход DQN часто страдает от чрезмерно оптимистичных оценок Q-value из-за смещения максимизации [34]. Подход DDQN смягчает чрезмерный оптимизм с помощью функции потерь (14)
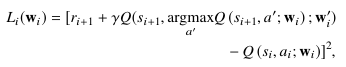
который, подобно DQN, использует веса для сети политики wi для выбора действий, но и использует замороженную цель вес сети w ′i чтобы оценить значение выбора. Этот подход, как было показано, значительно смягчает чрезмерный оптимизм, связанный с DQN, способствуя стабильности [33].
Второе расширение - это использование архитектуры рекуррентной нейронной сети (RNN) для обработки последовательностей данных таким образом, чтобы можно было разрешить долгосрочные зависимости [38]. В дополнение к полностью связанным скрытым слоям, описанным ранее, эта конфигурация использует слой длительной кратковременной памяти (LSTM) между конечным, полностью связанным скрытым слоем, и линейным выходным слоем. Эта архитектура известна как глубокая рекуррентная Q-сеть (DRQN) [32].
DRQN продемонстрировал впечатляющие эмпирические результаты в задачах доступа к спектру с лежащими в основе частично наблюдаемыми или шумными наблюдения за состоянием, которые могут быть обобщены как частично наблюдаемые MDPs (POMDPs) [39]. Здесь мы используем Keras API [40] для построения полностью связанных слоев и слоев LSTM, образующих DDRQN. Подобно вышеупомянутому DQN, мы используем три полностью связанных скрытых слоя и функции активации ReLU. Помехи радиолокационным системам связи часто имеют немарковскую структуру. Кроме того, методы зондирования спектра могут привести к шумным или ненадежным измерениям состояния.
Таким образом, существует необходимость как в стабильности, так и в разрешении долгосрочных зависимостей в процессе когнитивного радиолокационного обучения.
Мы предлагаем использовать функцию потерь DDQN, заданную (14), в тандеме с сетевой архитектурой DRQN для формирования Двойного DRQN (DDRQN). Несмотря на то, что DDRQN является простым продолжением этих двух методов, он демонстрирует превосходную производительность и стабильность при конвергенции когнитивных функций настройки радара, как показано в следующем разделе.
IV. РЕЗУЛЬТАТЫ СИМУЛЯЦИИ
A. Радиолокационная среда
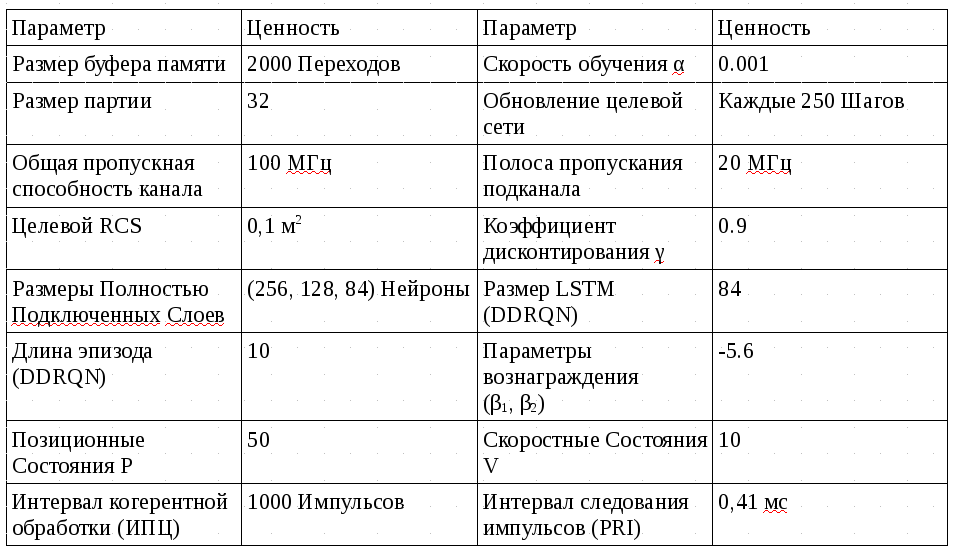
В этом разделе моделируется несколько сценариев сосуществования для оценки эффективности подхода Deep RL. Радиолокационная станция оценивается при наличии детерминированных, стохастических и регистрируемых сигналов помех. Для справки, производительность подхода Deep RL сравнивается с подходом итерации политики и схемой SAA, которая позволяет избежать помех, наблюдаемых на последнем временном шаге. Параметры, используемые для определения радиолокационной обстановки и характеристики
DQN и DDRQN, приведены в таблице I. Радиолокатор имеет интервал следования импульсов (PRI) 0,41 мс, что соответствует дальней эксплуатации за счёт доплеровских неоднозначностей [41].
Параметры вознаграждения β1 = 5 и β2 = 6 выбираются для обеспечения баланса между предотвращением помех и использованием полосы пропускания. Цикл из 1000 импульсов выбирается для наблюдения за поведением цели в течение длительного периода времени.
Цель имеет радиолокационное сечение (РКС) 0,1 м2, что характерно для малой авиации [41]. Целевое положение и скоростные состояния ограничены P = 50 и V = 10 соответственно, чтобы ограничить размер пространства действия состояний. Гиперпараметры нейронной сети выбираются вручную настройка на различные настройки, как правило, следуя методологии, изложенной в гл. 11 [35].
B. Поведение радара в стохастических средах
Сначала мы исследуем поведение радара в присутствии стохастически генерируемых прерывистых помех. Система связи работает в первом и втором из пяти подканалов, когда она активна, или θ= [1, 1, 0, 0, 0], и переключается между состояниями "включено" и "выключено" в соответствии с моделью цепи Маркова. Интерференция начинается в неактивном состоянии и изменяет состояние с вероятностью p на каждом временном шаге независимо от истории. Это важный инструмент для оценки производительности, поскольку помехи недетерминированы и имеют временную корреляцию, зависящую от параметра p, что свидетельствует о помехах, наблюдаемых во многих беспроводных сетях [42].
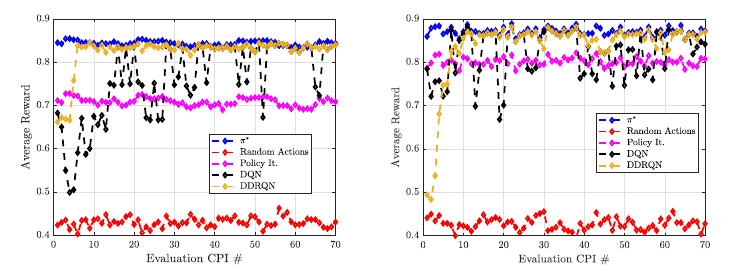
На рис. 3 мы наблюдаем поведение радара в случаях р = 0,4 и р = 0,2. В обоих случаях мы обучаем модели DQN и DDRQN в автономном режиме для 500 CPI и оцениваем производительность более 70 дополнительных CPI, отмечая среднее вознаграждение, получаемое в рамках CPI для изучения производительности и стабильности. Для сравнения мы применяем итерационный подход политики к 500 ИПЦ обучающих данных и отмечаем производительность на этапе оценки. Кроме того, мы анализируем эффективность принятия случайных действий, а также π∗ чтобы получить представление о лучшем и худшем случае производительности в стационаре.
В случае p = 0,4 подход DDRQN демонстрирует как хорошую среднюю производительность, так и стабильность, получая среднее вознаграждение выше 0,8 при сходимости и последовательно приближается к производительности стационарных π∗. Подход DQN достигает аналогичной максимальной производительности после автономного обучения, иногда приближаясь к π∗, но испытывает более высокую степень изменчивости, по-видимому, из-за нестабильности в процессе обучения, которую DDRQN способен смягчить с помощью дополнительного этапа проверки, связанного с двойным Qlearning, и возможностью разрешения более длительных временных корреляций, связанных с рекуррентным Q-обучением. Вполне вероятно, что DQN переоценил Q-значения, связанные с неоптимальными действиями из-за смещения максимизации, которого DDRQN избежал из-за дополнительной проверки. Оба глубоких метода RL превосходят итерацию политики с точки зрения среднего вознаграждения на этапе оценки, поскольку итерация политики не может установить точную модель T (s, a, s′) и R(s, a, s′) во время 500 циклов автономного обучения. Однако подход DQN иногда работает хуже, чем стабильная политика, изученная итерацией политики, из-за нестабильности в текущем процессе функций аппроксимации.
В случае р = 0,2 интерференция демонстрирует более сильную временную корреляцию между временными шагами, и в результате каждая техника получает более высокие вознаграждения на этапе оценки. Ещё раз, метод DDRQN приводит к сильной средней производительности и стабильности при сходимости, приближаясь к стационарному π∗ для большей части этапа оценки. Аналогично, DQN достигает хорошей производительности в среднем, но иногда испытывает падение среднего вознаграждения из-за неожиданных колебаний данных, что опять же, вероятно, связано с чрезмерным оптимизмом и невозможностью решить временные корреляции. Однако эти падения производительности менее серьёзны, чем в случае р = 0,4, и очень редко приводят к среднему вознаграждению ниже 0,7 за цикл. В то время как итерационный подход политики получает более низкое вознаграждение, чем любой из методов Deep RL, стационарная политика работает относительно хорошо по сравнению со случаем р = 0,4 из-за повышенной стабильности интерференционной картины.
Рис. 4. Поведение DQN в стохастической интерференции, порождённой нестационарной марковской моделью, где вероятность изменения состояния меняется со временем.
В сценариях динамического сосуществования распределение интерференционного канала может измениться внезапно и неожиданно. Таким образом, мы также исследуем эффективность каждого когнитивного радиолокационного подхода в нестационарной среде на рис. 4. В этой среде интерференция снова берётся из двух состояний марковской модели. Однако каждые 15 циклов, или 15 000 временных шагов, обозначенных вертикальными пунктирными линиями на рис. 4, вероятность изменения состояния р увеличивается следующим образом = 0.1 → 0.2 → 0.4 → 0.6 → 0.8.
Мы отмечаем на рис. 4, что, хотя производительность модели DDRQN немного страдает из-за первых двух изменений в распределении помех, подход в конечном итоге изучает стабильную политику, которая приближается к стационарному π∗ Таким образом, управляемый DDRQN радар способен плавно обобщаться на более резкие изменения помех позже в интервале оценки. Подход DQN аналогично изучает эффективную политику к концу интервала оценки, но испытывает снижение производительности примерно на 50 циклов, прежде чем приходит к стабильному поведению. Итерационный подход политики испытывает все более резкое падение производительности с каждым изменением распределения помех, демонстрируя поведение, близкое к наихудшему, как только параметр помех p = 0,8.
В этом разделе мы продемонстрировали способность когнитивного радара с управляемым Deep RL сосуществовать как со стационарными, так и с нестационарными стохастическими источниками помех с точки зрения сходимости в среднем получаемого вознаграждения. Учитывая фиксированный автономный период обучения 500 циклов, предлагаемые подходы Deep RL работают более выгодно по сравнению с итерацией политики, так как явное выражение T (s, a, s′) и R(s, a, s′) не требуется. Для дальнейшего изучения полезности предлагаемых глубоких RL-подходов мы рассмотрим важные радиолокационные показатели в следующем разделе.
С. Сравнение показателей радиолокационных характеристик
В этом разделе мы сравниваем показатели производительности радара, полученные с использованием подхода Deep RL к итерации политики и базовой схемы Sense-and-Avoid (SAA)— чутко-и-настороженно. Подход SAA выбирает самую большую смежную группу подканалов в ранее наблюдавшемся состоянии окружающей среды и не извлекает уроков из наблюдений за пределами времени t - 1. Однако SAA является вычислительно эффективным и может быть более эффективным, чем RL-подход, когда экологические модели трудно предсказать или необходимы очень быстрые реакции на изменение динамики окружающей среды. Кроме того, SAA может быть эффективным когда необходимы немедленные гарантии производительности, так как не требуется никакой фазы разведки.
Мы рассматриваем работу радара в детерминированных и стохастических средах в дополнение к спектральным данным, записанным в диапазоне 2450 МГц. Производительность радара оценивается с точки зрения среднего полученного SINR, столкновений, пропущенных возможностей и количества адаптаций формы сигнала. Мы вычисляем SINR, используя следующее выражение
(15)
где
РT - мощность передачи радара,
GT и GR - коэффициенты усиления передающей и приемной антенн,
λ - длина волны,
σ - поперечное сечение цели РЛС (RCS),
R - дальность действия цели,
k является постоянной Больцмана,
T0 — температура шума ,
L - общий коэффициент потерь,
и мы предполагаем, что мощность помех на РЛС PI заранее известна из начального периода пассивного зондирования, когда используется метод слепой оценки, такой как обнаружение энергии. Это предположение является разумным, если мощность передачи источника помех остаётся постоянной в течение интервала наблюдения.
Определение 3. Мы говорим, что адаптация формы сигнала происходит всякий раз, когда at ≠ at−1 Это соответствует различной форме сигнала LFM параметры между соседними импульсами.
Хотя предлагаемый подход не пытается оптимизировать скорость адаптации, он является важным параметром, поскольку значительная адаптация формы сигнала в рамках ИПЦ может привести к некогерентности полученных данных , что затрудняло бы обнаружение и сопровождение цели.
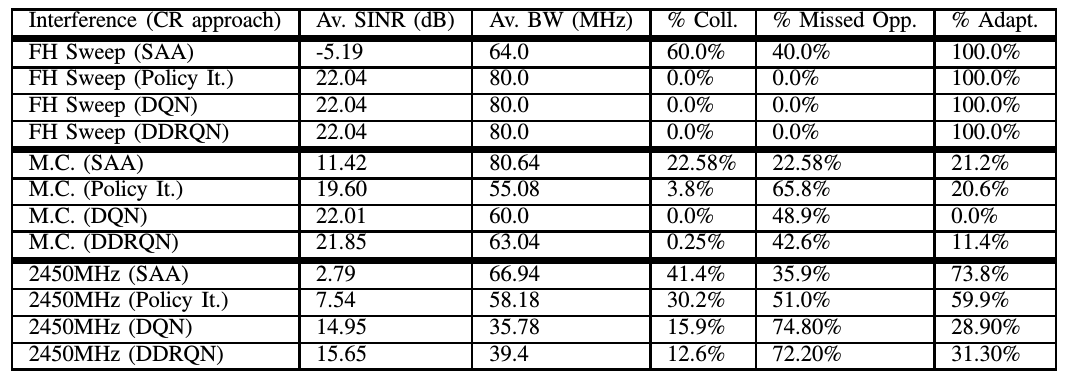
Первый тип помех, используемый для сравнения - это скачкообразная развёртка частоты, которая занимает один поддиапазон на каждом временном шаге и перемещается по каналу в повторяющейся схеме следующим образом: θ= [1, 0, 0, 0, 0] → [0, 1, 0, 0, 0] →[0, 0, 1, 0, 0] → [0, 0, 0, 1, 0] → [0, 0, 0, 0, 1]. Во-вторых, мы используем цепи Маркова как помехи в модель, которая занимает θ = [1, 1, 0, 0, 0] в активном режиме, как в предыдущем разделе. Этот источник помех начинается с выключенного состояния и переключается с вероятностью р =0,4. Тестовые и обучающие данные извлекаются независимо от цепи Маркова. Наконец, мы используем записанный образец RFI из канала 100 МГц с центром около 2450 МГц, который содержит нелицензированные сигналы Wi -Fi и Bluetooth. Эти записанные данные разделяются на сегменты обучения и оценки, которые происходят из одного и того же сбора данных. Агенты RL используют общую функцию вознаграждения, заданную (3).
В таблице II приведены показатели производительности для каждого типа помех. Мы наблюдаем, что для случая детерминированной скачкообразной развёртки частоты, каждый из методов RL является способен выучить одношаговый T (s, a, s′) и R(s, a, s′), где динамика явно выражена, и достигается оптимальная производительность с точки зрения упущенных возможностей и коллизий. Однако подход SAA в этом случае работает очень плохо, так как θt ≠ θt +1,∀ t, что нарушает предположение SAA о том, что θt = θt +1 Таким образом мы видим, что в тех случаях, когда T (s, a, s′) является детерминированным, все подходы RL эффективны при достаточном времени обучения. Однако глубокие методы RL могут быть полезны по сравнению с итерационным подходом политики, если время обучения ограничено, поскольку явная модель перехода и вознаграждения не требуется. Кроме того, если вероятности перехода детерминированы во многих состояниях, DDRQN может быть в состоянии лучше разрешить эти зависимости благодаря рекуррентной архитектуре LSTM.
При наличии стохастической интерференции цепи Маркова с р = 0,4 производительность подхода SAA улучшается по сравнению с развёрткой FH. Это происходит потому, что в среднем интерференция неподвижна в течение 1,5 временных шагов и часто остаётся неподвижной гораздо дольше. Однако метод итерации политики работает гораздо лучше с точки зрения сглаживания помех, так как R(s, a, s) даёт минимальное вознаграждение всякий раз, когда Nc ≥ 0. Подход DQN учит, что высокий награда может быть достигнута, полностью избегая поддиапазонов, содержащих помехи, и избегая все коллизии без адаптации формы сигнала. DDQN также избегает почти все коллизии, используя при этом немного большую пропускную способность, что приводит к меньшему количеству упущенных возможностей при лишь немного более низком среднем SINR, чем DQN. Регистрируемая интерференция 2450 МГц содержит множество сигналов, передаваемых во время сбора данных, и отражает переполненную спектральную среду. Здесь интерференция в значительной степени некогерентна между временными шагами, и подход SAA плохо работает с точки зрения как SINR, так и использования полосы пропускания. Итерационный подход к политике немного снижает скорость коллизий, но приводит к более низкому использованию полосы пропускания, чем SAA. Кроме того, глубокие подходы RL способны значительно уменьшить количество коллизий по сравнению с итерацией политики, что приводит к значительному улучшению SINR-по сравнению с другими методами, при этом DDRQN достигает самой низкой скорости столкновений. Однако, поскольку динамика перехода среды не является явной, частота упущенных возможностей значима для обоих методов. Таким образом, мы наблюдали, что управление когнитивной радарной системой, ориентированное на вознаграждение, улучшает показатели эффективности радара во многих сценариях сосуществования и в целом благоприятно по сравнению с реактивным подходом. В частности, Deep RL является жизнеспособным инструментом для изучения динамики окружающей среды без явных представлений T (s, a, s′) и R(s, a, s′). Это позволяет повысить производительность обобщения по сравнению с подходом итерации табличной политики. Кроме того, использование двойного обучения и архитектуры RNN обеспечивает когнитивную стабильность в процессе обучения и способность решать зависимости на многих временных этапах.
V. АППАРАТНАЯ РЕАЛИЗАЦИЯ И РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТОВ
В этом разделе мы представляем новую реализацию когнитивного радиолокационного управления Deep RL на прототипе программно-определяемого радара (SDRadar). Радар разработан с использованием универсального программного радиопередатчика (USRP) модели X310, который выбран за его низкую стоимость и гибкость. Дочерние платы USRP UBX160 RF обеспечивают достаточную производительность для проведения высококачественных радиолокационных измерений в интересующей нас мгновенной полосе пропускания 100 МГц, которая используется для тестирования сценарий сосуществования, который был смоделирован в предыдущем разделе. Установка SDRadar использует хост — персональный компьютер, который служит для управления системой и выполняет обучение агента Deep RL, а также другие операции обработки.

Алгоритм fast spectrum sensing (FSS) используется для обработки спектральных данных в режиме реального времени. Метод FSS быстро определяет вакансию поддиапазонов путем эмуляции быстрой обработки данных таламуса человека и подробно описан в работе [4]. После выполнения FSS данные спектра разбиваются на пять равноразмерных поддиапазонов для формирования вектора состояния бинарной интерференции θ, для обучения модели DQN мы используем только пассивный период зондирования или автономное обучение, в течение которого радар наблюдает радиочастотную среду и имитирует выполнение случайных действий для оценки Q-значений для каждого действия.
Это делается для экономии вычислительных ресурсов, так что выбор формы сигнала может быть выполнен в режиме реального времени. Q-значения получаются с использованием расчетного значения SINR и полосы пропускания, используемой во время каждого действия для расчета вознаграждения. На основе Q-значений, вычисленных в течение периода зондирования, радар затем компилирует таблицу, которая определяет, какие действия предпринять для любого сценария. Во время операций в режиме реального времени мы ограничены временным ограничением
(16)
Где Tws требуется ли время для выбора формы сигнала и TInt является временным интервалом помех. Поскольку мы занимаемся быстрой адаптацией формы сигнала, выбор действия непосредственно из таблицы поиска (LUT), сгенерированной из замороженного DQN
, позволяет нам быстро выбрать время выбора формы сигнала Tws. Однако онлайн-обновления Q(s, a) здесь не рассматриваются. Будущая работа будет сосредоточена на сокращении вычислительных ресурсов задач обработки сигналов, чтобы можно было проводить онлайн-обучение.
Как только автономная фаза обучения завершена, радар затем работает используя лучшее действие для каждого сценария, что достигается путём наблюдения состояния помехи, а также некоторого количества предыдущих состояний и использования LUT для выбора лучшего действия. Поскольку LUT устанавливается до начала передачи радара, радар способен экономить вычислительные ресурсы для других задач для завершения обработки в реальном времени. Эта реализация используется только при автономном обучении, и если окружающая среда резко изменится, сеть будет нуждаться в переобучении. Однако наши результаты показывают, что подход DQN дает лучшую производительность с точки зрения предотвращения RFI, чем аппаратная реализация алгоритма итерации политики MDP и простого метода SAA.
Для введения помех в окружающую среду мы используем приемопередатчик векторного сигнала (VST) в виде произвольной формы в качестве генератора волн для воспроизведения помех, записанных в физическом мире, или созданных синтетическим путём. Интерферирующий сигнал добавляется к низкочастотному чирп-сигналу радара с помощью радиочастотного сумматора. SDRadar подключается к главному компьютеру с помощью кабеля передачи данных 4x PCIe, который обеспечивает связь с низкой задержкой между ПК и SDR. Обработка в этой системе происходит в основном на хост-ПК, но также используется шина ПЛИС (FPGA) радиопередатчика USRP для некоторых задач обработки сигналов.

Подход DQN меняет свою форму волны реже, что приводит к менее заметным доплеровским боковым лепесткам.
A. Результаты экспериментов
Здесь мы снова заинтересованы в том, чтобы использовать как можно больший доступный спектр не вызывая взаимных помех. Однако наша главная цель состоит в том, чтобы улучшить характеристики радиолокационного обнаружения и слежения с помощью этого подхода, поэтому мы также заинтересованы в дальнодействующем доплеровском отклике когерентно обработанных данных. Таким образом, мы исследуем полученную статистику SINR и полосы пропускания для анализа использования радиолокационного спектра. Кроме того, мы используем графики дальности Доплера и алгоритм постоянного срабатывания ложных тревог (CFAR) для проверки эффективности обнаружения радара.
Обратная связь от обработки данных радара сообщает, каким образом вознаграждения радара должны быть наилучшим образом адаптированы к конкретной среде, в то время как сами вознаграждения дают представление о том, насколько хорошо радар выполняет поставленную перед ним задачу. Хотя было бы полезно разработать функцию вознаграждения, основанную исключительно на результатах радиолокационной обработки, получение немедленной обратной связи относительно результатов отдельных действий может быть затруднено, поскольку требуется когерентная обработка. Поэтому мы используем функцию вознаграждения, чтобы смягчить упущенные возможности и коллизии на основе импульс-импульс.
Этот метод был оценён путём прямого сравнения с аппаратной реализацией итерационного
подхода политики MDP, а также подхода SAA без прогнозирующих возможностей. Избегание RFI для каждого метода оценивается после того, как результаты радара по каждому методу когерентно обрабатываются и согласованно фильтруются в операции постобработки. Здесь
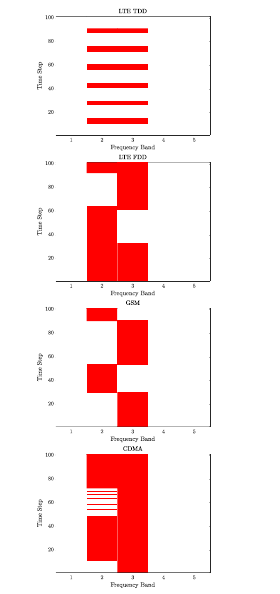
интервал повторения импульсов (PRI) составляет 409,6 мкс, а цикл состоит из 1000 импульсов (0,41 с). Длительность чирпа LFM составляет 20 мкс. RFI, рассматриваемые для этого сравнения, являются двоичными представлениями записанных изменяющихся во времени сообщений сигналы, которые включают в себя LTE дуплексное разделение частот - Frequency Division Duplexing (FDD), LTE дуплексное разделение по времени - Time Division Duplexing (TDD), GSM и CDMA схемы, образцы которых можно увидеть на рис. 5.
В таблице III мы видим средние значения SINR после когерентной обработки и согласованных операций фильтрации для подхода SAA наряду с итерацией политики MDP и
когнитивными движками DQN. Для случаев FDD и GSM реактивный режим способен избежать большей части RFI, но все же испытывает некоторые коллизии, поскольку он не может предсказать переходы. Как и итерация политики, так и DQN предоставляют небольшие преимущества SINR для этих случаев, поскольку потребность в предсказательных прогнозах в этих сценариях присутствует, но ограничена.
Улучшение SINR от DQN наиболее заметно для данных TDD LTE, где улучшение примерно на 10 дБ видно из подхода итерации политики, который, в свою очередь, является улучшением примерно на 8 дБ по сравнению с реактивным методом. DQN обеспечивает такое значительное улучшение по сравнению с итерацией политики благодаря преимуществу дополнительной памяти. Поскольку интерференция следует предсказуемому шаблону, DQN может захватить это, посмотрев на последние три состояния RFI, в отличие от итерации политики, которая может смотреть только на одно состояние при принятии решений.
Ещё одним потенциальным преимуществом подхода DQN в аппаратно реализованной системе является то, что радар имеет тенденцию выбирать одно и то же действие много раз, если он надёжно обеспечивает высокое значение добротности. Если радар обучен конвергенции, мы, как правило, видим стабильные средние значения добротности. Это обычно приводит к меньшей адаптации формы передающего сигнала, что может помочь смягчить боковые лепестки в доплеровской области. На рис. 6 виден дальномерный доплеровский отклик радаров при итерации политики и задействованном DQN, игнорирующих записанный 100 МГц сигнал RFI из центральной полосы частот 2450 МГц. Цель очень велика при более заметном использовании политики DQN по сравнению с итерационным подходом к политике, поскольку обрабатываемые данные являются более согласованными. В то время как искажающие эффекты от гибкости импульсов могут быть исправлены методами обработки сигналов, такими как алгоритм деконволюции Ричардсона-Люси или неидентичное многократное сжатие импульсов (NIMPC) [43], подход DQN может снизить необходимость вычислительно дорогостоящей постобработки.
Чтобы количественно оценить производительность Deep RL в аппаратной реализации, мы также исследовали производительность радиолокационного обнаружения и сравнили ее с
алгоритмом итерации политики и традиционной схемой радиолокации, которая всегда использует полную интересующую полосу радиодиапазона. Мы сравнили эффективность обнаружения с помощью алгоритма CFAR и генерации кривых рабочих характеристик приемника (ROC), которые учитывают скорости положительного обнаружения — Positive Detection (PD) и ложной тревоги — False Alarm (FA) для различных порогов обнаружения целей. Каждая точка на ROC соответствует 500 циклам полученных радиолокационных данных, каждый продолжительностью 0,41 сек. Для каждой точки мы используем CFAR для расчёта теоретической частоты ложных тревог, которая определяет обнаружение порог. Скорости PD и FA измеряются следующим образом:
(17)
(18)
где N - количество исследуемых циклов, МDj - число пропущенных обнаружений, если мы знаем, что цель присутствует в окружающей среде, и NP- количество точек в двухмерном доплеровском диапазоне. Результаты анализа CFAR для радиолокатора, работающего на 100 МГц RFI, записанного из полос с центром 1750 МГц и 2450 МГц в среде кампуса, представлены на рис.7.

Таким образом, мы наблюдаем, что использование агентов RL для радиолокационного контроля приводит к значительному сдвигу кривой производительности влево в пространстве ROC по сравнению с традиционной работой РЛС, демонстрируя снижение количества ложных тревог при положительной скорости обнаружения. Кроме того, подход DQN приводит к значительному повышению производительности по сравнению с подходом итерации политики. Это происходит из-за увеличения SINR в когерентно обработанных данных при использовании DQN, чтобы избежать RFI и более низких доплеровских боковых лепестков в Доплера-диапазоне из-за более совершенного паттерна действия агента Deep RL в каждом сценарии.
Здесь мы предложили агента DQN в качестве жизнеспособного когнитивного движка для игнорирования изменяющегося во времени RFI и несмотря на то, что радар должен быть обучен перед началом работы, как только обучение будет завершено, радар способен быстро предпринимать наилучшие действия без значительных требований к обработке, обеспечивая эффективную работу в системе реального времени. Кроме того радар способен прогнозировать и избегать изменяющегося во времени RFI более точно, чем ранее предложенный метод итерации политики, что приводит к более высокому среднему SINR для обработанных данных допплеровского диапазона, и повышению производительности обнаружения при использовании алгоритма CFAR, что можно увидеть в пространстве ROC через уменьшение количества ложных тревог для заданного количества истинных обнаружений. Будущая работа по этой реализации будет сосредоточена на сокращении обработки, выполняемой хост-ПК, таким образом, чтобы онлайн-обучение могло происходить во время работы радара.
VI. ЗАКЛЮЧЕНИЕ И БУДУЩИЕ НАПРАВЛЕНИЯ
Эта работа представила и продемонстрировала эффективную структуру Deep RL для когнитивной радиолокационной системы с разделением спектра. Предложенный подход использует нелинейную аппроксимацию функций с помощью глубоких нейронных сетей для оценки значения пар состояние-действие непосредственно из опыта радара. Предложенная схема обучения использует глубокое Q-обучение для стабилизации процедуры аппроксимации функций с помощью воспроизведения опыта и медленно обновляющейся целевой сети. Кроме того, было показано, что расширение DQL, который использует двойное обучение в тандеме с архитектурой RNN, способен достичь очень хорошей средней производительности и стабильности при наличии как стационарных, так и нестационарных стохастических помех.
Когнитивная радиолокационная система способна найти решение, которое улучшает эффективность обнаружения, действуя в перегруженной спектральной среде, развивая поведение, чтобы максимизировать функцию вознаграждения. Таким образом, разработка функции вознаграждения, которая точно мотивирует желаемое поведение радара, является основной проблемой при использовании этого метода. Мы показали с помощью моделирования и экспериментальных результатов, что функция вознаграждения, которая в первую очередь учится избегать коллизий с RFI и, во вторую очередь учится использовать как можно больше непрерывной полосы пропускания при условии отсутствия коллизий, является эффективной стратегией обучения для улучшения показателей эффективности радаров.
Подход Deep RL показал значительное улучшение характеристик радара по сравнению с ранее предложенным подходом итерации политики MDP, что видно как в имитационном моделировании, так и в экспериментальных результатах аппаратного прототипа. Самым большим преимуществом является меньшая размерность, необходимая для разработки решения по сравнению с итерацией политики, поскольку радару не нужно изучать явные модели перехода и вознаграждения окружающей среды. Это позволяет радару более эффективно учиться в тех случаях, когда окружающую среду трудно охарактеризовать. Кроме того, схема Deep RL способна масштабироваться до большие пространства состояний-действий более эффективны, позволяя большему количеству CSI управлять решениями радара в сложных сценариях.
Ещё одним преимуществом подхода Deep RL является то, что используется аппроксимация функций, позволяющая радару обобщать более эффективно, чем подход итерации политики, который страдает по производительности при изменении одношаговой динамики среды. Использование аппроксимации функций обновляет значение многих пар состояние-действие на основе одного опыта, что позволяет повысить производительность обобщения при появлении ранее невидимых состояний.
Хотя Deep RL является эффективным и практичным методом для обеспечения совместного использования спектра радара, существует несколько связанных с этим проблем. Во-первых, глубокие нейронные сети часто требуют значительных исследований, чтобы расчитать большое количество весов, необходимых для достаточной производительности. Кроме того, регулярное изменение полосы пропускания и центральной частоты чирп-сигнала в пределах цикла может привести к значительным искажениям в доплеровской области [43]. Иерархическая схема обучения, которая учится на основе данных дальномерной доплеровской обработки в дополнение к обратной связи от радиолокационных импульсов, может быть эффективным способом смягчения этого эффекта, а также может быть развита в будущих исследованиях.
Иерархическое обучение для когнитивного радара было кратко исследовано в работе [45], но эмпирический успех иерархических алгоритмов RL [46] требует дальнейшего изучения в контексте динамического разделения спектра. Кроме того, в этой работе использовался длительный автономный период обучения, когда радар исследует эффект принятия случайных действий. Однако в приложениях, где во время обучения должны быть соблюдены минимальные гарантии эффективности, может быть оправдан подход on-policy, такой как SARSA [34], и он также может стать предметом будущих исследований.
Deep RL представляет собой многообещающий прогрессивный путь для контроля когнитивных беспроводных систем, которые должны работать во все более перегруженных сценариях совместного использования спектра. Хотя ещё предстоит проделать значительную работу по разработке надёжных алгоритмов, пригодных для общей радиочастотной среды, этот подход представляет собой жизнеспособное решение, которое может быть объединено с предметными знаниями в качестве шага к более общим, автономным и интеллектуальным когнитивным радиолокационным системам.
РЕФЕРЕНЦИИ
[1] Федеральная комиссия по связи (FCC), “Spectrum Horizons,” Кормил. Архивариус, том 84, № 107, июнь 2019 г.
[2] Партнерский проект третьего поколения (3GPP), “5G в выпуске 17 -Сильная радиоэволюция”, Белая книга.
[3] Х. Гриффитс, Л. Коэн, С. Уоттс, Э. Моколе, К. Бейкер, М. Уикс и др. S. Blunt, “Radar Spectrum Engineering and Management: Technical and Regulatory Issues”, Proc. IEEE, vol. 103, no. 1, pp. 85-102, Jan.2015.
[4] А. Ф. Мартон, К. И. Ранни, К. Шербонди, К. А. Галлахер и С. Д. Блант, “Распределение спектра для некооперативного сосуществования радаров", IEEE Trans. Аэрос. Электрон.Сист., том 54, № 1, с. 90-105, авг.2017.
[5] С. Хайкин, “Когнитивный радар: путь будущего", IEEE Sig. Proc.Mag., vol. 23, no. 1, pp. 30-40, Jan. 2006.
[6] А. Ф. Мартон, “Когнитивный радар демистифицирован", Вестник УСРИ, № 350, с. 10-22, 2014.
[7] М. С. Греко, Ф. Джини, П. Стинко и К. Белл, “Когнитивные радары: На Путь к Реальному Прогрессу До сих пор и Возможности для будущего”, IEEE Sig. Proc. Mag., vol. 35, no. 4, pp. 112-125, July 2018.
[8] B. Jiu et al., “Оптимизация формы широкополосной когнитивной радиолокационной волны для совместная оценка радиолокационной сигнатуры цели и обнаружение цели,” IEEE Trans. Аэрос. и элек., vol. 51, no. 2, pp. 1530-1546, Jun.2017.
[9] Н. Шарага, Дж. Табрикян и Х. Мессер, “Оптимальный когнитивный луч-формирование для сопровождения цели в MIMO Radar/Sonar,” IEEE J. Sel. Proc., vol. 9, no. 8, pp. 1440-1451, Dec. 2015.
[10] P. Moo and Z. Ding, Adaptive Radar Resource Management. Aca-demic Press, 2015.
[11] Z. Ji и K. Liu, “Когнитивные радиоприемники для динамического доступа к спектру - Динамический обмен спектром: Теоретический обзор игры,” IEEEComm. Mag., vol. 45, no. 5, pp. 88-94, May 2007.
[12] B. Ravenscroft et al., “Экспериментальная демонстрация и анализ Когнитивное зондирование спектра и надрезы для радара”, IET Radar, Sonar и Nav., том 12, № 12, С. 1466-1475, октябрь 2018 г.
[13] B. H. Kirk et al., “Избегание изменяющейся во времени радиочастоты Интерференция С Программно-Определяемым Когнитивным Радаром”, IEEE Trans. Ага. Электрон. Сист., том 55, № 3, С. 1090-1104, декабрь 2018 г.
[14] М. Р. Белл, “Теория информации и радар: взаимная информация и радиолокация".the design and analysis of radar waveforms and systems", Ph. D.dissertation, California Institute of Technology, 3 1988.
[15] Э. Сельви, Р. М. Бюрер, А. Мартоне и К. Шербонди, “Рейн-например, Обучение для адаптивных радаров слежения за полосой пропускания,” IEEE Trans. Аэрос. Электрон. Сист., Появиться, 2020.
[16] М. Л. Путерман, Марковские процессы принятия решений.Джон Уайли и сыновья Inc., 2005.
[17] К. Арулькумаран, М. П. Дейзенрот, М. Брундаж и А. А. Бхарат, “Глубокое Подкрепление Обучения: Краткий Обзор", IEEE Sig. Proc. Mag., vol. 34, no. 6, pp. 26-38, Nov. 2017.
[18] М. Кози, Дж. Ю, Р. М. Бюхер, А. Мартон и К. Шербонды, “Применение сетей Deep-Q для отслеживания целей для улучшения когнитивного радара", в Proc. IEEE Radar Conf., Apr. 2019.
[19] К. Л. Белл, К. Дж. Бейкер, Г. Э. Смит, Дж. Т. Джонсон и М. Ран-gaswamy, “Cognitive Radar Framework for Target Detection and Tracking", IEEE J. Темы в Сиг. Proc., vol. 9, no. 8, pp. 1427–1438, Dec. 2015.
[20] J. Mukerjee, P. Sheehan и T. Caelli, “Investigating Human Machine Интеграционные концепции для классификации Isar”, in Proc. Int. Commun., Nav. и Surv. Конф. (ICNS) Июнь 2019 года.
[21] A. R. Chiriyath, B. Paul и D. W. Bliss, “Radar-Communications Конвергенция: сосуществование, сотрудничество и совместное проектирование”, IEEE Trans. на Cogn. Commun. и Netw. - том 3, № 1, с. 1-12, март 2017 г.
[22] C. Sturm, T. Zwick, and W. Wiesbeck, “An OFDM System Concept для совместных радиолокационных и коммуникационных операций”, - говорится в сообщении. Конф., июнь 2009.
[23] Q. Zhao and B. M. Sadler, “A Survey of Dynamic Spectrum Access,” IEEE Sig. Proc. Mag., vol. 24, no. 3, pp. 79-89, May 2007.
[24] P. Stinco, F. Gini и M. Greco, “Spectrum sensing and sharing for когнитивные радары,” IET Radar, Sonar and Nav., vol. 10, no. 3, pp. 595–602, Feb. 2016.
[25] K. Gerlach et al., “Спектральное обнуление при передаче через нелинейную ЧМ Радиолокационные сигналы”, IEEE Trans. Аэрос. Электрон. Syst., vol. 47, no. 2,pp. 1507-1515, Apr. 2011.
[26] В. Куцуридис, “Когнитивные модели цикла восприятие-действие: взгляд из мозга”, в Proc. Intl. Совместная конференция по нейрохимии. Netw., август 2013 г.
[27] А. Н. Пинеда и др., “Система радиолокационного слежения с использованием контекстуальной информации-размышления об архитектуре нейронной сети в маневрировании воздушным боем”, Intl. Jour. of Distributed Sensor Netw., vol. 9, no. 8, Aug. 2013.
[28] L. Wang et al., “Многоцелевое обнаружение и адаптивная форма сигнала Design for Cognitive MIMO Radar", IEEE Sensors Journal, vol. 18, no. 24, pp. 9962-9970, Dec. 2018.
[29] Дж. Меткалф, С. Д. Блант и Б. Химед, “Подход к машинному обучению к когнитивному радиолокационному обнаружению”, в Proc. IEEE Radar Conf., Apr. 2015, стр. 1405-1411.
[30] J. Wang et al., “Network Association in Machine-Learning Aided Cognitive Radar and Communication Co-Design, " IEEE J. Sel. Районы в коммуне. том 37, № 10, октябрь 2019 г.
[31] V. Mnih et al., “Контроль на человеческом уровне через глубокое подкрепление learning", Nature, vol. 518, pp. 529-533, февраль 2015 г.
[32] М. Хаускнехт и П. Стоун, “Глубокое рекуррентное Q-обучение для частично наблюдаемых MDPS”, in AAAI Fall Symposium Series, vol. 9, no. 8, Sep. 2015, pp. 29-36.
[33] H. van Hassel, A. Guez и D. Silver, “Deep Reinforcement Learning с двойным Q-обучением”, в Proc. Конф. об искусственном интеллекте (AAAI), февраль 2016, с. 2094-2099.
[34] Р. С. Саттон и А. Г. Барто, Обучение подкреплению: введение-тион The MIT Press, 2018.
[35] I. Goodfellow, Y. Bengio и A. Courville, Deep Learning. Массачусетский технологический институт Пресса, 2015.
[36] З. Yang,Y.Се,иZ.Ван,“А Теоретический Анализ от Глубокий Q-Обучение,” Май 2019.
[Онлайн]. Доступно: https://arxiv.org/abs/1901.001...
[37] GoogleBrain, - Тензорный поток.” [Онлайн]. Доступно: https://www.tensorflow.org/
[38] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory", Neural Вычисление, vol. 9, no. 8, pp. 2094-2099, Nov. 1997.
[39] Y. Xu, J. Yu, and R. M. Buehrer, “The Application of Deep Re-применение Обучения распределенному доступу к спектру в динамических гетерогенных средах с частичными наблюдениями,” IEEE Trans. Беспроводная связь., 2020.
[40] F. Chollet et al., “Keras,” https://keras.io
[41] М. И. Скольник, Справочник по радиолокации. McGraw-Hill, 2008.
[42] М. Хенги и Р. К. Ганти, Интерференция в больших беспроводных сетях. Теперь Издательство, 2009.
[43] Б. Х. Кирк, А. Ф. Мартон, К. Д. Шербонди и Р. М. Нараянан, “Смягчение искажения цели в импульсно-гибких датчиках с помощью деконволюции Ричардсона–Люси”, Electronics Letters, vol. 55, no. 23, pp. 1249-1252, Nov 2019.
[44] Т. Хиггинс, К. Герлах, А. К. Шеклфорд и С. Д. Блант, “Аспекты неидентичного кратного импульсного сжатия”, в Proc. IEEE Radar Conf., май 2011 г.
[45] A. F. Martone et al., “Metacognition for Radar Coupitance", in Proc.IEEE Intl. Radar Conf., Апр. 2020.
[46] А. Г. Барто и С. Махадеван, “Последние достижения в иерархической Усиление обучения,” Дискретно-событийные динамические системы, т. 13, С. 41-77, январь 2003 г.




Оценили 3 человека
7 кармы