

Ну что ты будешь делать с нежелающими читать самостоятельно?
Как обычно проводятся исследования? Вы полагаете, что один раз взяв образцы у той или иной группы населения, исследовав их и накатав научный труд, опубликовав его, всё тут-же выкидывается, кроме книжек?
Ан нет. Образцы древесины, скажем, после дендроанализа хранятся и постепенно накапливаются целые древохранилища. То же самое происходит и с другими вещдоками, например, образцами для генетических исследований. Особенно, для масштабных. Ибо сбор образцов - дело довольно трудоёмкое и затратное. А потому, для нового исследования используется часть уже имеющихся образцов (либо обработанных данных), а часть образцов собирается с нуля (в зависимости от цели исследования).
Увидев пару строчек текста, как можно делать такие глобальные выводы?
Статья научная: http://journals.plos.org/plosg...
Генетическое наследие экспансии тюркоязычных кочевников по Евразии
Извлечение (или резюме) - первое, что мы можем увидеть в статье, кроме авторов.
Тюркские народы представляют собой разнообразный набор этнических групп, определяемых тюркскими языками. Эти группы рассеялись по обширной территории, включая Сибирь, Северо-Западный Китай, Центральную Азию, Восточную Европу, Кавказ, Анатолию, Ближний Восток и Афганистан. Происхождение и история раннего расселения тюркских народов оспаривается, причем кандидаты на свою древнюю родину простираются от Закаспийской степи до Маньчжурии в Северо-Восточной Азии. Предыдущие генетические исследования не выявили четкого унифицирующего генетического сигнала для тюркских народов, который предоставляет поддержку для замены языка, а не демографическую диффузию как модель для расширения тюркского языка. Мы обратились к генетическому происхождению 373 особей из 22 тюркоязычных популяций, представляющих их нынешний географический ареал, путем анализа данных генотипа с высокой плотностью генома. В соответствии с моделью языковой экспансии элитарного доминирования большинство изучаемых тюркских народов генетически напоминают своих географических соседей. Тем не менее, западнотюркские народы, отобранные по Западной Евразии, имели избыток длинных хромосомных путей, идентичных по происхождению (ВБД), с населением из современной Южной Сибири и Монголии (ССМ), область, где историки сосредотачивают ряд ранне-тюркские и - тюркские степные народы. Хотя в популяциях, не относящихся к тюркским языкам, наблюдаются ССМ, соответствующие трассам IBD (> 1 сМ), в тюркских народах этот процент выше (на уровне 0.01) выше, чем у их не тюркских соседей. Наконец, мы использовали метод ALDER и предполагали даты примесей (~ IX-XVII вв.), Которые пересекаются с тюркскими миграциями V-XVI вв. Таким образом, наши результаты указывают на историческую примесь среди тюркских народов, а недавняя общая родословная с современными популяциями в SSM поддерживает одну из гипотетических родин для их кочевых тюркских и родственных монгольских предков.
Резюме Авторов:
Столетия кочевых миграций в конечном итоге привели к распространению тюркских языков на обширном пространстве от Сибири, Центральной Азии до Восточной Европы и Ближнего Востока. Несмотря на глубокое культурное воздействие, оставленное этими кочевыми народами, мало что известно об их доисторическом происхождении. Более того, поскольку современные тюркскоязычного происхождения склонны генетически напоминать своих географических соседей, неясно, оставили ли их кочевые предки идентифицируемый генетический след. В этом исследовании мы показываем, что тюркоязычные народы, опробованные на Ближнем Востоке, на Кавказе, в Восточной Европе и в Центральной Азии, имеют разную пропорцию азиатских предков, которые происходят в одном регионе, в Южной Сибири и Монголии. Монгольское и тюркоязычное население этой области имеет необычно большое количество длинных хромосомных путей, которые идентичны по происхождению тюркским народам со всей Западной Евразии. Распад индуцированной примесью неравновесности сцепления по хромосомам в этих популяциях указывает на то, что примесь произошла в IX-XVII вв., в соответствии с исторически зафиксированными тюркскими кочевыми миграциями и позднее монгольской экспансией. Таким образом, наши результаты показывают генетические следы недавних крупномасштабных кочевых миграций и отображают их источник на ранее предполагаемую область Монголии и южной Сибири.
(текст, идущий далее, ответа на наш вопрос не содержащий оставляю для любознательных, а Вас, Штирлиц, попрошу сразу пройти вместе со мной до выделенного тремя галками заголовка )
Введение
Лингвистическую связанность часто используют для информирования о генетических исследованиях [1], и здесь мы идем по этому пути, чтобы восстановить аспекты крупного и относительно недавнего демографического события, расширения кочевых тюркоязычных народов, которые изменили большую часть западно-евразийского этнолингвистического ландшафта В течение последних двух тысячелетий. Современное тюркоязычное население является в значительной степени оседлым народом; Они насчитывают более 170 миллионов по всей Евразии и, после периода миграций, охватывающих период V-XVI вв., Имеют широкий географический разброс, охватывающий Восточную Европу, Ближний Восток, Северный Кавказ, Центральную Азию, Южную Сибирь, Северный Китай и Северо-Восточную Сибирь [2-4].
Существующее разнообразие тюркских языков, на которых говорят в этом обширном географическом разрезе, отражает только недавнюю (2100-2300 лет) историю расхождения, которая включает в себя крупный раскол на Огур (или Болгар) и Общность тюркских языков [5, 6]. Этому периоду предшествовал ранний древнетюркский язык, для которого нет исторических данных и длительная прототюркская стадия, если в 4500-4000 г.г. до н. Э. Существовало тюрко-монгольское лингвистическое единство (протоязык) [7, 8].
Самые ранние тюркские правители (между 6 и 9 веками) были сосредоточены в том, что сейчас является Монголией, северным Китаем и южной Сибирью. Соответственно, этот регион был выдвинут в качестве отправной точки для расселения тюркоязычных пастушеских кочевников [3, 4]. Мы обозначаем его здесь как «Внутренняя Азиатская Родина» (IAH) и отмечаем по крайней мере два вопроса с этой рабочей гипотезой. Во-первых, в той же самой приблизительной области ранее доминировала Империя Xiongnu (Hsiung-nu) (200 г. до н.э.-100 н.э.), а затем короткоживущая Конфедерация Сиань-сь (100-200 гг. Н.э.) и Руран (ака Хуан-цзюань или азиатский авар) (400-500 гг. Н. Э.). Эти степные политики, вероятно, были созданы не тюркскими языками и предположительно объединились в этнически разнообразные племена. Только во второй половине VI в. Тюркоязычные народы получили контроль над регионом и образовали быстро расширяющийся каганат Гектюрк, которому вскоре овладели многочисленные ханства и каганаты, простирающиеся от северо-восточного Китая до понтийско-каспийских степей в Европе [2] -4]. Во-вторых, Göktürks представляет собой самую раннюю из известных этнических групп, в которой тюркские народы появляются под именем Turk. Тем не менее, тюркоязычные народы появляются в письменных исторических источниках до этого времени, а именно, когда огурические тюркоязычные племена появляются в Северных Причерноморских степях в 5-м веке, намного раньше, чем возникновение Гектюркского каганата в ИАХ [9]. Таким образом, ранние этапы тюркского расселения остаются малоизученными, и наше знание об их древней среде обитания остается рабочей гипотезой.
Предыдущие исследования на основе Y-хромосомы, митохондриальной ДНК (мтДНК) и аутосомных маркеров показывают, что, в то время как тюркские народы из Западной Азии (анатолийские турки и азербайджанцы) и Восточной Европы (гагаузы, татары, чуваши и башкиры) в целом генетически подобны своим Географические соседи, они действительно демонстрируют незначительную долю как мтДНК, так и Y гаплогрупп, что характерно для Восточной Азии [10-15]. Ожидается, что среднеазиатские тюркские носители (кыргызы, казахи, узбеки и туркмены) больше разделяют свой унипартарный генофонд (9-76% Y-хромосомы и более 30% мтДНК-линий) с восточноазиатскими и сибирскими популяциями [16, 17]. В этом отношении они отличаются от своих южных не тюркских соседей, включая таджиков, иранцев и представителей различных этнических групп в Пакистане, кроме Хазары. Однако эти исследования не направлены на то, чтобы идентифицировать точный географический источник и время прибытия или смешивания восточно-евразийских генов среди современных тюркоязычных народов. «Восточная» мтДНК и тем более Y-хромосомные линии (с учетом разрешения, доступного исследованиям того времени) не имеют географической специфики, чтобы четко различать регионы в Северо-Восточной Азии и Сибири и / или тюркские и не тюркские носители языка В регионе [18, 19].
В нескольких исследованиях, в которых используются данные SNP-панели по всему геному, описывается генетическая структура популяций в Евразии, и хотя некоторые из них включают в себя различные тюркские популяции [15, 20-24], они не сосредоточены на выяснении демографического прошлого тюркоязычного континуума. В тех случаях, когда для сравнения доступно более одного географического соседа, тюркоязычные народы генетически близки к своим не тюркским географическим соседям в Анатолии [22, 25], на Кавказе [15] и в Сибири [21, 23]. Недавний опрос населения во всем мире показал, что в трех тюркских популяциях (турки, узбеки и уйгуры) был обнаружен сигнал (13-14 вв.) И одно не тюркское население (лезгины) с монголами (из северного Китая), даурсы Говорящего на монгольском языке) и хазарей (монгольского происхождения) [26]. Это исследование также показало наличие примесей (относящихся к домонгольскому периоду 440-1080 гг. Н.э.) среди не тюркских (за исключением чувашей) восточноевропейских и балканских народов с исходной группой, связанной с современными орокенами, монголами и якутами. Это первое генетическое доказательство исторического потока генов из северокитайского и сибирского источников в некоторые северные и центральные евразийские популяции, но неясно, относится ли этот сигнал к другим тюркским популяциям через Западную Евразию. Здесь мы спрашиваем, возможно ли это Чтобы идентифицировать явный генетический сигнал (ы), разделяемый всеми тюркскими народами, которые, вероятно, произошли от предполагаемых доисторических кочевых турок. В частности, мы проверяем, имеют ли разные тюркские народы генетическое наследие, которое можно отнести к гипотетическому ИАХ. Более конкретно, мы спрашиваем, произошло ли это общее происхождение в исторический период времени, что подтверждается избытком длинных хромосомных трактов, идентичных по происхождению между тюркоязычными народами Западной Евразии и населяющими ИАХ. Для решения этих вопросов мы использовали массив генотипирования с высокой плотностью генома для генерации данных о тюркоязычных народах, представляющих все основные ветви языковой семьи (рис. 1B).
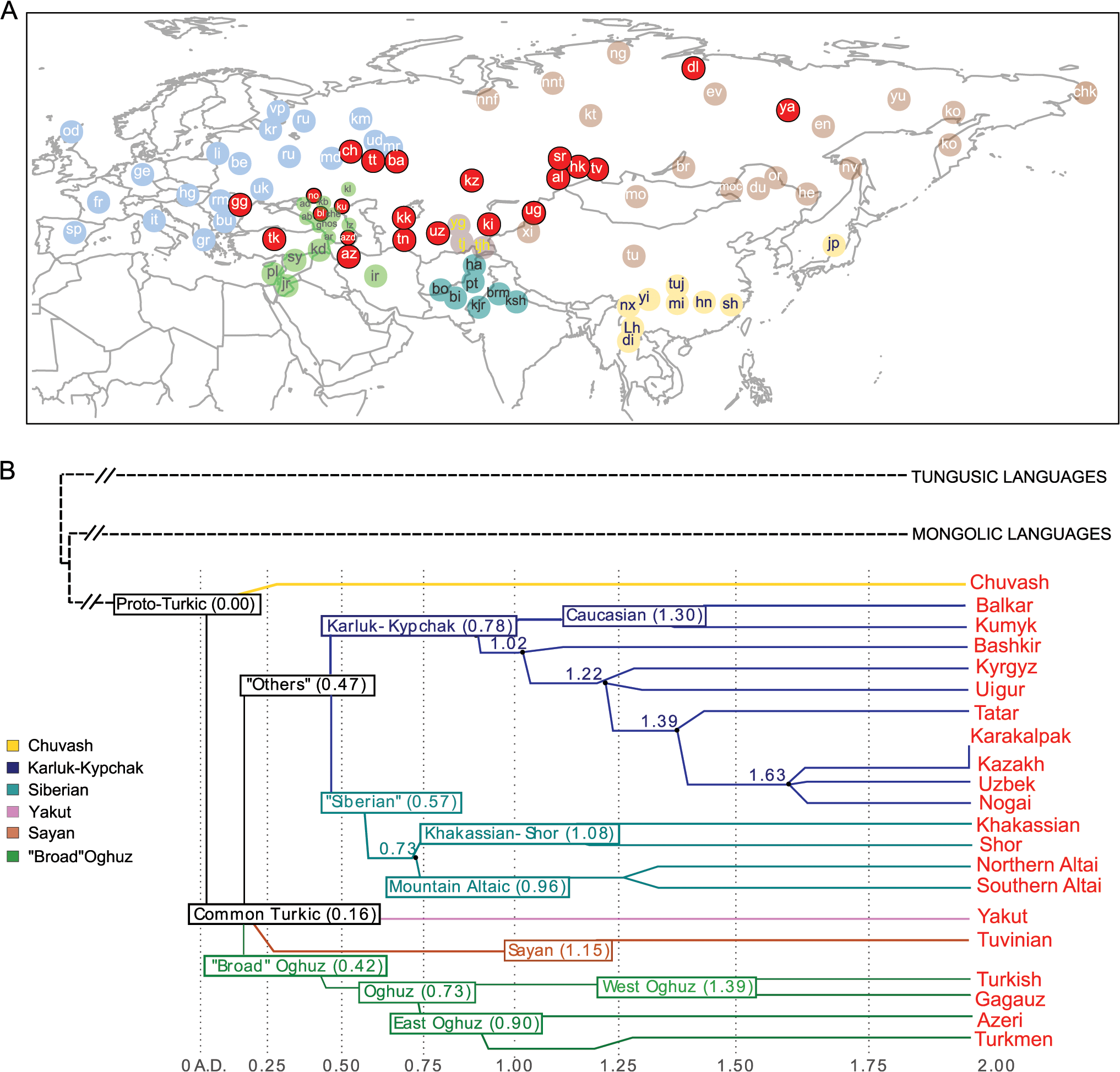
Рис. 1. Географическая карта образцов, включенных в данное исследование, и лингвистическое дерево тюркских языков.
Панель А) В нетурецкоязычных группах показаны светло-голубые, светло-зеленые, темно-зеленые, светло-коричневые и желтые круги в зависимости от региона. Тюркоязычные популяции показаны красными кругами независимо от региона выборки. Полные имена населения приведены на S1 Таблица B) Лингвистическое дерево тюркских языков адаптировано из Dybo 2004 и включает только те языки, на которых говорят тюркские народы, проанализированные в этом исследовании. Ось x показывает шкалу времени в кило-годах (кья). Внутренние ветви показаны разными цветами.
Http://dx.doi.org/10.1371/journal.pgen.1005068.g001
Результаты
Чтобы охарактеризовать популяционную структуру тюркоязычных популяций в контексте их географических соседей по всей Евразии, мы генотипировали 322 новых образца из 38 евразийских популяций и объединили его с ранее опубликованными данными (см. Таблицу S1, материалы и методы для деталей), чтобы получить Общий набор данных из 1444 образцов, генотипированных по 515 841 маркерам. Новые образцы, представленные в этом исследовании, географически охватывают ранее недопредставленные регионы, такие как Восточная Европа (Волго-Уральский регион), Средняя Азия, Сибирь и Ближний Восток. Мы использовали STRUCTURE-подобный подход, реализованный в программе ADMIXTURE [28], чтобы исследовать генетическую структуру в евразийских популяциях, выведя наиболее вероятное количество генетических кластеров и пропорций смешивания, соответствующих наблюдаемым данным генотипа (от K = 3 Через K = 14 групп) (S1 Fig). Как показано в предыдущих исследованиях [15, 20, 29], популяции в Восточной Азии обычно содержали аллели, которые находят членство в двух общих кластерах, показанных здесь как k6 и k8, в модели, предполагающей популяцию K = 8 «предков» (рис. 2). Географически зона распространения этих двух компонентов (кластеров) была сосредоточена в Сибири и Восточной Азии, соответственно. Их общая распространенность снизилась, когда один из них двигался на запад от Восточной Азии (корреляция с долготой, p = 8,8 × 10-16, R = 0,77, 95% ДИ: 0,66-0,85). В целом, аллели тюркских популяций, отобранных по Западной Евразии, показали принадлежность к одному набору генетических кластеров Западной Евразии, k1-k4, как и их географические соседи. Кроме того, племена волжско-уральских тюрков (чуваши, татары и башкиры) также представили членство в кластере k5, в котором находились сибирские уралоязычные популяции (нганасаны и ненцы) и распространялись на некоторых европейских уральских ораторов (Марис, Удмуртов и коми). Однако в большинстве случаев тюркские народы показали более высокое совместное присутствие «восточных компонентов» k6 и k8, чем их географические соседи.
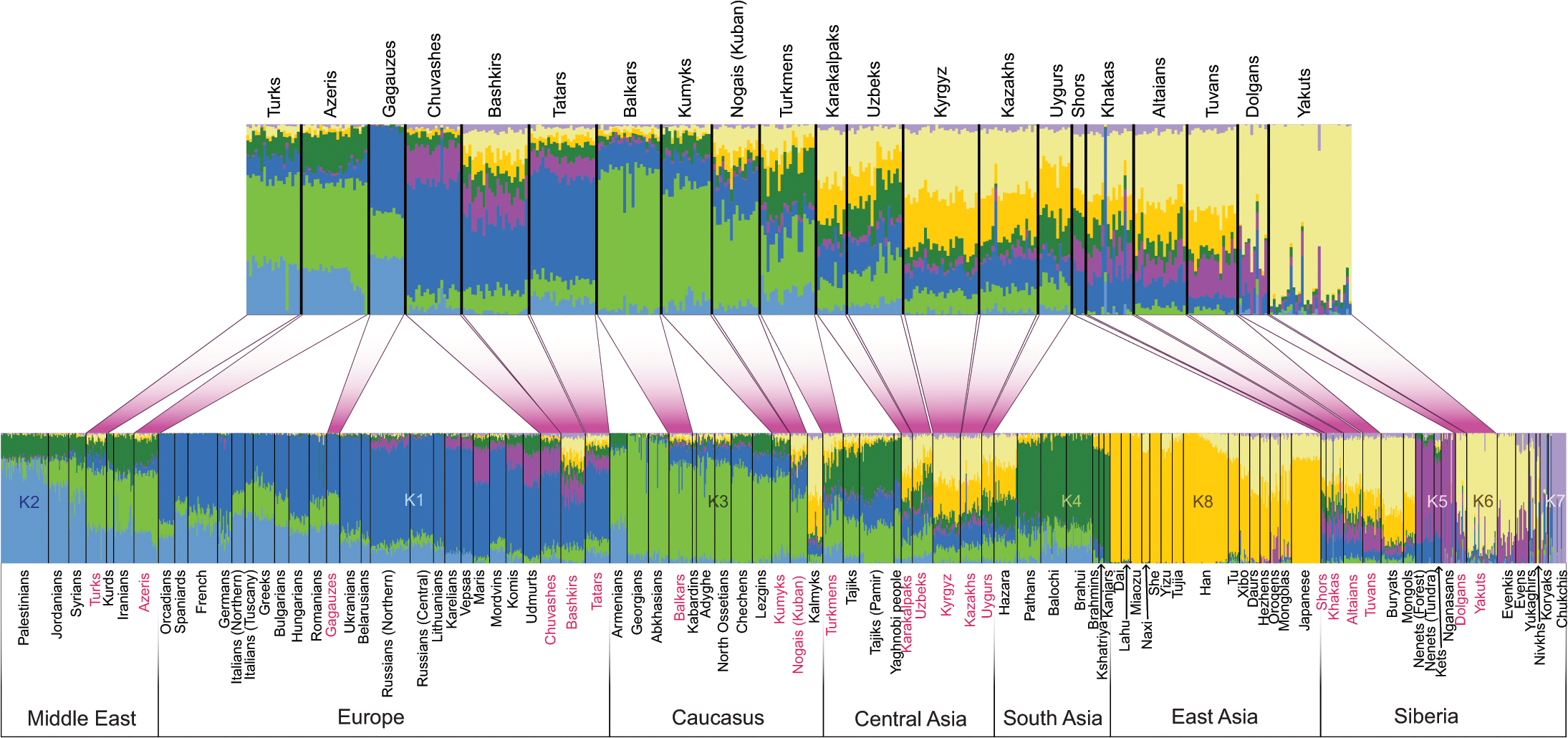
Рис. 2. Структура населения, выведенная с использованием анализа ADMIXTURE.
Результаты ADMIXTURE при K = 8 показаны. Каждый человек представлен вертикальной (100%) стопкой столбцов, указывающей пропорции родословной в К, построенных популяциями предков. Тюркоязычные популяции показаны красным цветом. На верхнем графике показаны только тюркоязычные популяции.
Http://dx.doi.org/10.1371/journal.pgen.1005068.g002
Тест с тремя популяциями
«Восточные компоненты» k6 и k8, выведенные среди тюркских и не тюркских народов через Западную Евразию, а также «западные компоненты» k1, k2 и k3, присутствующие среди сибирских популяций, могут возникнуть в результате эпизодов распространения генома в противоположных направлениях в Прошлом, и эта история популяционного смешения может быть статистически проверена с использованием f3-статистики [30, 31]. Для оценки сценариев добавок, предложенных в анализе ADMIXTURE, мы протестировали все три комбинации популяций в нашем наборе данных, используя тест трех популяций (f3-статистика) [30, 31]. Мы сообщали только популяционные трионы f3 (target, source1, source2) с наиболее отрицательной f3-статистикой (таблица S2) и считали, что популяции значительно смешивались, когда их Z-счет был меньше 1,64 (т.е. p-значение было меньше 0,05, Для одностороннего теста). Наши тесты с тремя популяциями показали, что почти все западно-евразийские тюркские народы (15 из 16) и их нетюркские соседи (49 из 61) (см. Таблицу S2 для географического подразделения) были смешаны с восточно-азиатскими и сибирскими Населения. Аналогичным образом, все популяции сибирских тюрков, а также некоторые (11 из 27) восточно-евразийских не тюркских популяций показали сигнал о примеси к популяциям, связанным с Западной Европой. При интерпретации результатов f3-статистики важно указать, что сообщенные исходные популяции не обязательно представляют истинные смешающие популяции [31]. Хотя точные исходные популяции были неопределенными, значительная отрицательная f3-статистика дала убедительные доказательства для примеси в большинстве тюркских и не тюркских популяций в нашем наборе данных. Чтобы проверить, являются ли эти сигналы примеси результатом недавних событий потока генов, мы в дальнейшем исследовали распределение длинных хромосомных трактов, разделяемых между популяциями в нашем наборе данных.
Географическое распространение недавних общих родословных
Недавнее исследование показывает, что даже пара неродственных людей из противоположных концов Европы делят сотни хромосомных путей ВЗК от общих предков, которые жили в течение последних 3000 лет. Количество таких недавних предков уменьшается экспоненциально с географическим расстоянием между парами популяций, и такая зависимая от расстояния картина может быть искажена из-за расширения популяции или потока генов [32]. Мы наблюдали достаточно высокую корреляцию (коэффициент корреляции Пирсона = 0,77, 95% ДИ: 0,76-0,79, р <2,2 × 10-16) между скоростью распада IBD и географическим расстоянием в нашем наборе евразийских популяций. Эта зависящая от расстояния картина, вероятно, формируется как изоляцией на расстояние, так и потоком генов: многие популяции смешиваются (отрицательная f3-статистика в таблице S2), и существует долговременное зависимое снижение распространенности «восточных компонентов», K6 и k8. Некоторые популяции могут выделяться в этом зависимом от расстояния образце из-за изоляции, большего потока генов или генетического дрейфа. Например, когда мы удалили из нашего набора данных западно-евразийские тюрки (пробы на Ближнем Востоке, на Кавказе, в Восточной Европе и Средней Азии), мы наблюдали лучшую корреляцию между распадом совместного распределения IBD и географическими расстояниями между популяциями (коэффициент корреляции Пирсона = 0,83 , 95% ДИ: 0,82-0,85, р <2,2 × 10-16). Для идентификации популяций, для которых обмен IBD с тюркоязычными популяциями отличается от зависящего от расстояния распада, мы сначала вычислили распределение IBD (средняя длина генома IBD, измеренного в centiMorgans) для каждого из 12 западнотюркских популяций со всеми другими популяциями в наборе данных (Таблица S3), а затем вычитали ту же статистику, рассчитанную для их географических соседей (подробности см. В разделе «Материалы и методы» и S2 Fig для схематического представления этого анализа). Когда различия были наложены на все 12 тюркских популяций, мы обнаружили необычно высокий сигнал накопления IBD (образцы отмечены «плюсом» на рис. 3A-3C) для популяций за пределами Западной Евразии. Коррелированный сигнал совместного использования IBD для этих отдаленных популяций превысил ожидания, основанного на зависящей от расстояния структуре распада. Большинство этих отдаленных популяций расположены в Южной Сибири и Монголии (ССМ) и в Северо-Восточной Сибири, за исключением двух образцов в Восточной Европе (Марис) и на Северном Кавказе (калмыки). В принципе, когда мы сравниваем паттерн распределения ИБД таким образом между соседними тюркскими и не тюркскими популяциями, мы можем наблюдать высокий сигнал о совместном ВБД с некоторыми популяциями Сибири из-за дрейфа в одной из популяций по сравнению, но вероятность того, что такие случайные сигналы Будет коррелировать между несколькими тюркскими популяциями и накапливаться в одном регионе, ничтожно. Действительно, нулевая гипотеза для этого анализа не предполагала систематической разницы между любым тюркским населением и их соответствующими географическими соседями. Поэтому нулевая гипотеза предсказывает, что случайные различия накапливаются во всем географическом ареале западнотюркских популяций. Чтобы продемонстрировать это нулевое ожидание, мы заменили каждую из западнотюркских популяций популяциями, случайно выбранными из наборов соответствующих нетюркских соседей, и повторили этот анализ вычитания / накопления, как показано на S2 Fig. Когда наборы случайных не тюркских образцов Были протестированы, накопленный сигнал был ограничен популяциями (обозначен «плюсовым символом» на S3 Fig) в пределах Западной Евразии, как и ожидалось нулевой гипотезой. Есть, однако, два исключения (нганасанцы и ненцы), которые при тщательном рассмотрении предлагают интересный вывод, согласующийся с нашими результатами ADMIXTURE. Эти две сибирские популяции, Nganasans и Nenets (S3A, S3B, S3E, S3I и S3J Fig) говорят на уральских языках и демонстрировали высокий накопленный сигнал только тогда, когда в наших тестируемых наборах были западные уральские ораторы (Maris, Komis, Vepsas и Udmurts) . Это соответствовало нашим результатам ADMIXTURE (рис. 2), поскольку компонент родословной k5 был определен специально между этими западными оралоязычными ораторами и двумя сибирскими уралоязычными нганасанцами и ненцами. Теперь вернемся к общей разнице между накопленным сигналом разделения IBD при нулевой гипотезе (см. S3 Fig) и наблюдаемым для множества западных тюркских популяций (рис. 3). Некоторые популяции в ССМ и Северо-Восточной Сибири продемонстрировали сильный сигнал о совместном ВБД с популяциями западных тюрков, и эта картина, скорее всего, указывает на недавний поток генов из Сибири. Чтобы сузить источник этого потока генов, важно знать, какое из сибирских популяций является коренным для их текущего местоположения. Мы показываем в разделе «Обсуждение», что только тувинцы, буряты и монголы из области SSM являются коренными по отношению к их текущим местоположениям (по крайней мере, в пределах известного исторического времени), и поэтому эта область является лучшим кандидатом на источник потока недавних генов в Западных тюрков. Следует отметить, что эта направленность на восток-запад подразумевается тем фактом, что 12 популяций, отобранных по разным западноевропейским регионам, вряд ли будут показывать коррелированный сигнал о высоком распределении ВБД с одним регионом, если они не получат от него поток генов. Действительно, когда мы повторили наш анализ случайным выбором не тюркских популяций (S2 Fig), мы не смогли воспроизвести подобный коррелированный сигнал.
Параллельный ВБД, основанный на длинных сегментах 1-2 см.
Для каждой популяции, упорядоченной вдоль оси x, совместное использование IBD вычисляется с тремя популяциями SSM (тувинцы, буряты, монголы) и эвенки. Каждое тюркоязычное население (показано красным) сгруппировано с соответствующими географическими соседями, используя круглые скобки. Сгруппированные географические соседи объединялись и использовались для выполнения теста перестановки, как описано в разделе M & M. Красные цифры под названием тюркского населения указывают, сколько популяций SSM демонстрирует статистически значимое превышение распределения IBD с данным тюркским населением. Обратите внимание, что, например, башкиры, татары и чуваши делятся своими географическими соседями.
Рис.4 см. здесь Http://dx.doi.org/10.1371/journal.pgen.1005068.g004
Пространственная картина в совместном использовании IBD была отмечена, когда тракты IBD разных классов длин считались отдельно. Для сегментных классов 1-2 cM и 2-3 cM более высокое разделение IBD является статистически значимым для большинства тюркских ораторов, за исключением гагаузов и чувашей (и татар в случае 2-3 cM). Для более длинных трактов IBD 3-4 см, статистические данные для более высокого совместного распределения IBD становятся более слабыми в некоторых образцах на Ближнем Востоке и на Кавказе (азербайджанцы, кумыки и балкарцы). Под более слабыми доказательствами мы имеем в виду, что статистически значимое превышение совместного использования ВБД ограничивалось подгруппой четырех тестируемых кандидатов-предков. В Приволжско-Уральском регионе для одного и того же класса сегментов (3-4 см) только башкиры продолжали демонстрировать убедительные доказательства генных потоков, а татары и чуваши - нет. Для этих двух тюркоязычных популяций не все тесты были статистически значимыми, так как фоновая группа, из которой были сделаны перестановленные выборки, содержала популяцию мари, говорящую на финском языке, которая показывает сопоставимые уровни азиатской примеси (рис. 2) и распределения IBD (S4 Fig). Когда мы рассматривали даже более длинные сегменты (4-5 см и 5-6 см), мы больше не наблюдали систематического избытка совместного использования IBD для тюркских народов на Ближнем Востоке, на Кавказе или в Волго-Уральском регионе. Напротив, популяции, расположенные ближе к зоне SSM (узбеки, казахи, кыргызы и уйгуры, а также башкиры из Приволжско-Уральского региона), все же продемонстрировали статистически значимое превышение распределения ВБД. Эта пространственная картина может быть частично объяснена относительной редкостью более длинных трактов IBD по сравнению с более короткими и повторными событиями потока генов в популяции, ближе к области SSM.
Встречайте возраст азиатской примеси с помощью методов ALDER и SPCO
Согласно историческим записям, тюркские миграции происходили в основном в течение ~ V-XVI вв. (Мало что известно о более ранних периодах) и частично совпадают с монгольской экспансией. Предполагая, что 30 поколений за поколение, обычные сибирские предки различных тюркских народов жили до и во время этого миграционного периода между 20 и 53 поколениями назад. Ожидаемая длина однопутного тракта IBD, унаследованного от общего предка, который прожил ~ 20-53 поколения назад, колеблется между 2,5 и 0,94 сантиморганцами (подробности см. В разделе «Методы»). Принимая во внимание, что многопутевые пути IBD будут в среднем более длинными [33], сигнал совместного использования IBD при 1-5 сМ, обнаруженный между народами Западной тюрки и населением района SSM, может быть вызван историческими тюркскими и монгольскими расширениями от SSM площадь. Можно приблизительно очертить возраст общих предков непосредственно из распределения общих трактов IBD [32], но такой вывод был бы слишком грубым для наших целей. Здесь мы используем два различных метода, реализованных в ALDER [34] и SPCO [35], чтобы определить возраст сибирской / азиатской примеси среди тюркских народов. Даты добавок для всех проанализированных тюркских народов (рис. 5 и таблица S4) относятся к историческим временным рамкам (5-17 вв.), Которые пересекаются с периодом кочевых миграций, вызванных тюрками (VI-XVI вв. Н. Э.) И монгольскими экспансиями XIII в.) [2, 3]. Тем не менее, индивидуальные даты смешения, оцененные с использованием этих двух методов, частично перекрываются и являются дискордантными для большинства популяций (рис. 5). Поэтому мы смоделировали серию событий примеси, охватывающую целевой исторический период, и сравнили, как эти два метода выполнялись (подробности см. В разделе «Материал и методы»). Даты, полученные ALDER, как правило, ближе к моделируемым истинным значениям, тогда как SPCO последовательно оценивает несколько более старые даты (рис. 6). Важно отметить, что датированные SPCO даты для нашего реального набора данных (рис. 5) также имели тенденцию быть более старыми, и поэтому мы подозреваем предвзятость в наших оценках SPCO. Далее мы обсудим только даты, которые были определены с помощью ALDER.
Даты смешения тюркоязычных популяций в абсолютной дате.
Синие круги показывают оценки по ALDER-inferred point, а ошибки показывают 95% -ные доверительные интервалы. Серые круги показывают оценки SPCO-inferred point, а столбцы ошибок в сером указывают 95% -ные доверительные интервалы. Красная полоса показывает диапазон оценки точек (по ALDER) по всем проанализированным образцам, а оранжевая полоса показывает то же самое для дат SPCO-inferred. Даты смешивания до общей эры (CE) показаны с отрицательным знаком.
Рис 5 Http://dx.doi.org/10.1371/journal.pgen.1005068.g005
Даты смешивания для смоделированных популяций.
Моделированные популяции были получены путем смешивания двух популяций предков G поколениями назад, как описано в разделе M & M. Мы повторяли каждый сценарий добавления 120 раз и анализировали с использованием двух методов датирования примесей: ALDER и SPCO. Круги представляют собой даты примесей для одного смоделированного населения, а цвет окружности указывает метод вывода примеси, как показано в легенде. Красные «плюс символы» показывают истинную дату добавления.
Рис.6 Http://dx.doi.org/10.1371/journal.pgen.1005068.g006
Смешанный сигнал неравновесного сцепления в смешанной популяции «восстанавливается» с использованием двух суррогатов (контрольных популяций), и когда проверено несколько таких пар, ALDER позволяет сравнить их генетическую близость с истинными популяциями смешивания на основе амплитуды взвешенного LD Кривой [36]. Следует, однако, отметить, что выводы, сделанные таким образом, могут вводить в заблуждение, когда исходная популяция, генетически связанная с истинным микширующим населением, подвергается самой добавке. В этом случае другая менее родственная популяция будет выведена как лучший суррогат для истинной смешанной популяции. Мы рассмотрели все возможные комбинации популяций в нашем наборе данных в качестве ссылок на тюркоязычные популяции и сообщим о наборе «лучших» пар (таблица S4), демонстрирующих наибольшую амплитуду взвешенной кривой ЛД. Интерпретация этих результатов, однако, сложна, поскольку некоторые из этих ссылок смешиваются сами по нашим трем популяционным тестам (таблица S2). Мы не можем исключить возможность того, что некоторые из ссылок, действительно связанных с историческими предками, дали меньшую амплитуду, потому что они были примешаны. Например, популяции SSM, которые продемонстрировали сигнатуру недавнего потока генов (избыток путей IBD) в западнотюркских популяциях, показали более низкую амплитуду взвешенной добавки LD по сравнению с несмешанными ссылками, которые мы сообщали в таблице S4. Популяции SSM значительно замечены (см. Таблицу S2), и это, вероятно, произошло во время тюркского миграционного периода (таблица S4).
Хотя мы сообщаем об одной дате добавления каждой популяции, мы отмечаем, что вполне вероятно, что современные тюркские народы были установлены несколькими волнами миграции [2-4, 37]. Действительно, тюркские народы, расположенные ближе к области SSM (из Приволжско-Уральского региона и Средней Азии), показали более низкие даты по сравнению с более отдаленными группами населения, такими как анатолийские турки, иранские азербайджанцы и северокавказские балкарцы. Из этого пространственного рисунка выделяются только ногайцы, бывшие кочевые племена степного пояса и кумыки, обитающие на северных склонах Кавказа.
Обсуждение
Наш анализ ADMIXTURE (рис. 2) показал, что тюркоязычные популяции, разбросанные по всей Евразии, имеют тенденцию разделять большую часть своей генетической родословной со своими нынешними географическими не тюркскими соседями. Это особенно очевидно для тюркоязычных народов в Анатолии, Иране, на Кавказе и в Восточной Европе, но труднее определить для северо-восточных сибирских тюркских ораторов, якутов и долганцев, для которых нетуртские референтные популяции отсутствуют. Мы также обнаружили, что более высокая доля азиатских генетических компонентов отличает тюркских ораторов по всей Западной Евразии от их ближайших не тюркских соседей. Эти результаты подтверждают модель о том, что экспансия тюркской языковой семьи за пределы ее предполагаемого восточно-евразийского ядра происходила в основном за счет замены языка, возможно, с помощью сценария доминирования элиты, то есть интрузивные тюркские кочевники навязывали свой язык коренным народам из-за преимуществ в военной и / Или социальной организации.
Когда тюркские народы переселялись через Западную Евразию, сравниваются со своими не тюркскими соседями, они демонстрируют более высокий уровень обмена ВБД с популяциями ССМ и Северо-Восточной Сибири (рис. 3). Есть, однако, две несибирские популяции, которые также демонстрируют высокий уровень обмена ВБД с обследованными тюркскими народами, калмыками и марисом. Эти исключения требуют тщательного рассмотрения в свете исторических данных и ранее опубликованных исследований. Например, монголоязычные калмыки мигрировали на Северный Кавказ из Джунгарии (северо-западная провинция Китая на монгольской границе) только в 17 веке [37], в то время как Марис выделяется из других географических соседей из-за необычно высокой недавней примеси с башкирами : Они демонстрируют более высокий обмен IBD с башкирами для всех классов длины тракта IBD (от 1-2 см до 11-12 см) по сравнению с другими популяциями в регионе (p <0,05). Это можно объяснить тем, что мы собрали образцы марис в Республике Башкортостан, где они, по-видимому, в какой-то мере вступали в смешанные браки с башкирами. Наконец, некоторые из сибирских популяций на самом деле являются мигрантами в их нынешнем местонахождении. Например, якуты, эвенки и долганы в основном происходят из района озера Байкал, который по сути является зоной ССМ [23]. Оказывается, что большинство популяций, демонстрирующих высокий уровень обмена IBD с западнотюркскими популяциями, происходят из области SSM или имеют примесь с одним из исследованных тюркских популяций. Единственное исключение - нганасаны; Они демонстрируют необычно высокое разделение IBD как на западнотюркских народов (рис. 3), так и случайно выбранных не тюркских популяций (S3 Fig). Учитывая, что популяции SSM (тувинцы, монголы и буряты) можно надежно считать коренными по отношению к их местонахождению и что все остальные сибирские и несибирские популяции (демонстрирующие высокий уровень распределения IBD с западнотюркскими народами на рис. 3), все имеют происхождение SSM , Мы предполагаем, что популяции предков из этой области способствовали недавнему потоку генов в народы Западной тюрки. Мы отмечаем, что SSM, соответствующие трассам IBD, также наблюдались со значительной частотой среди некоторых не тюркских народов, таких как адыгэ, марис, северные осетины и удмурты (рис. 4 и S4 рис.), Предполагая, что поток генов из области SSM также способствовал -Туркические популяции. В этой связи нельзя исключать альтернативные объяснения, не связанные с тюркскими и монгольскими миграциями, но эти исторические события остаются наиболее вероятным сценарием, поскольку высокая доля совпадающих трактов ССМ является объединяющим признаком многих народов Западной Тюрки и таким коррелированным сигналом Разделение с сибирскими популяциями не наблюдается ни для какой другой группы популяций (S3 Fig). Таким образом, вполне вероятно, что мигранты происхождения ССМ взаимодействовали со многими предками современного западноевропейского населения, но именно более сильное взаимодействие (отраженное в более высоком разделении IBD) с предками мигрирующих SSM, которые вели тюркизацию. Мы провели тест на перестановку для каждой западной тюркской популяции, и наблюдаемый избыток совместного распределения IBD (по сравнению с не тюркскими соседями) с популяциями области SSM был статистически значимым (рис. 4 и S4 рис.).
Другим важным результатом нашего анализа совместного использования IBD является вывод о том, что две из трех популяций SSM, которые мы считаем «исходными популяциями» или современными прокси для популяций-источников, являются как говорящими на монголоязычных языках. Это наблюдение можно объяснить несколькими способами. Например, можно предположить, что завоевания монголов, начиная с XIII века, сопровождались их демографической экспансией по уже занятым территориям, в частности, тюркскими носителями, что привело к смешению между тюркскими и монгольскими ораторами. В качестве альтернативы, также вероятно, что предки тюркских и монгольских племен происходят из одного и того же или почти одного и того же района и подвергались многочисленным эпизодам примеси до их соответствующих экспансий.
Последнее объяснение косвенно свидетельствует сложная, долговременная стратиграфия монгольских заимствованных слов в тюркских языках и наоборот [38]. Первое объяснение маловероятно с исторической точки зрения, так как хотя монгольские завоевания были начаты войсками Чингисхана в начале XIII века, хорошо известно, что они не предполагали массовых переселений монголов над завоеванными территориями. Вместо этого монгольская военная машина постепенно расширялась различными тюркскими племенами по мере их расширения, и таким образом тюркские народы в конечном итоге усиливали свое распространение по евразийской степи и за ее пределами [39]. Поэтому мы предпочитаем второе объяснение, хотя мы не можем полностью исключить монгольский вклад, особенно в свете дат дат, которые совпадают с монгольским периодом расширения.
Наконец, наш анализ распределения IBD показал, что область SSM является источником недавнего потока генов. Этот район является одной из гипотетических родины для тюркских народов и лингвистически связанных монголов. В то время как присутствие Монгольской империи над этой территорией хорошо зафиксировано, одних исторических источников недостаточно, чтобы однозначно связать эту область с тюркской родиной по нескольким причинам: некоторые тюркские группы, говорящие на огурической ветви тюркских языков, были засвидетельствованы западными в Понтийско- Каспийские степи в середине-конце V в. Это географически удалено от области SSM, и временно намного раньше, чем империя Гектюрк была создана в районе SSM. Таким образом, в нашем исследовании представлены первые генетические данные, подтверждающие, что один из ранее гипотетических ИАХ находился вблизи Монголии и Южной Сибири.
Поток генов из области SSM, который мы вывели на основании нашего анализа распределения IBD, также должен быть обнаружен с использованием альтернативного подхода, такого как ALDER, который основан на анализе паттернов неравновесия сцепления (LD) из-за примеси. Используя метод ALDER, мы протестировали все возможные комбинации ссылочных групп в нашем наборе данных. Паттерны затухания LD, наблюдаемые среди западнотюркских популяций, были совместимы с примесью между западноевропейскими и восточноазиатскими / сибирскими популяциями (см. Обнаруженные контрольные популяции в таблице S4). Примесь, датируемая множеством восточноазиатских / сибирских популяций (таблица S4), выводила события примеси в диапазоне от 816 до н.э. для чувашей и 1657 н.э. для ногайцев. Мы выбрали эти контрольные популяции, исходя из самых высоких амплитуд кривой ЛД, как предполагают авторы метода. Примечательно, что все популяции SSM, которые, по предположению, являлись источником потока SSM-гена, либо отфильтровывались по процедуре предварительного тестирования ALDER из-за общего сигнала примеси с тестируемыми тюркскими популяциями, либо имели более низкую амплитуду взвешенного LD По сравнению с несмешанными ссылками. Действительно, как мы показываем, популяции SSM и два северо-восточных сибирских популяций все продемонстрировали статистически значимый сигнал примеси между тем же набором популяций Западной Евразии и Восточной Азии, что и народы Западной Тюрки (таблица S2 и таблица S4). Таким образом, набор контрольных популяций, указанных в таблице S4, демонстрирующих наивысшую амплитуду кривой ЛД, фактически представляет собой набор неимеющихся контрольных популяций (таблица S2), которые прошли процедуру фильтрации ALDER. Этот фильтр удаляет любую ссылочную совокупность, которая показывает общий сигнал примеси с тестируемой совокупностью. Для нашего исследования было важно, что диапазон дат ALDER-предполагаемой примеси совпадает с крупными тюркскими миграциями, а затем и с монгольским распространением (рис. 5), которые, как известно, вызывают кочевые миграции в Средневековую Среднюю Азию, Ближний Восток и Европу. Кроме того, при учете лингвистической классификации и регионального контекста мы нашли параллели с крупномасштабными историческими событиями. Например, современные татары, башкиры, казахи, узбеки и кыргызы простираются от бассейна Волги до гор Тянь-Шаня в Центральной Азии, однако (рис. 5) свидетельствуют о недавней примеси в XIII-XIV вв. . Эти народы говорят на тюркских языках кипчакско-карлукской ветви, и их возраст примесей позволяет утверждать предполагаемые миграции предков-турок-кипчаков из Иртыша и Обской области в XI веке [37]. Есть исключения, такие как балкары, кумыки и ногайцы на Северном Кавказе, которые показали либо более ранние даты примеси (8-й век), либо значительно более позднюю примесь между 15-м веком (кумыки) и 17-м веком (ногайцами).
Чуваши, единственные сохранившиеся огурские ораторы, показали более старшую дату пришествия (IX век), чем их соседи, говорящие по-кипчакски в Поволжье. Согласно историческим источникам, когда в VII веке Онугур-Болгарская империя (северные черноморские степи) распалась, некоторые ее остатки мигрировали к северу вдоль правого берега Волги и установили то, что позднее стало называться Волжскими болгарами, Из которых первые письменные знания появляются в мусульманских источниках лишь в конце IX века [40]. Таким образом, сигнал примеси для чувашей близок к предполагаемому времени прибытия огурцев в Поволжье.
Различия в датах добавок для трех огузских популяций (азербайджанцев, турок и туркмен) были заметны, и их географическое положение указывает на возможное объяснение. Анатолийские тюрки и азербайджанцы, чьи среднеазиатские предки пересекли иранское плато и стали в значительной степени недоступными для последующего генных потоков с другими тюркскими носителями, как свидетельствуют о более ранних событиях примеси (XII и IX вв. Соответственно), чем туркмены. Туркмены, оставшиеся в Центральной Азии, показали значительно более недавнюю примесь, датированную XIV веком, в соответствии с другими тюркскими народами Центральной Азии и, скорее всего, из-за смешения с более свежими, возможно, повторяющимися волнами мигрантов в регионе от ССМ. Наша коллекция образцов, которая охватывает всю распространенность нынешнего распределения тюркских народов, показывает, что большинство тюркских народов имеют значительную долю своего генома со своими географическими соседями, поддерживая модель элитного доминирования для распространения тюркского языка. Мы также показали, что почти все западнотюркские народы сохранили в своем геноме общую родословную, которую мы проводим в регионе ССМ. Таким образом, мы предоставляем генетические доказательства для Внутренней Азии родины (ИАХ) первопроходцев носителей тюркского языка, ранее выдвинутых другими на основе исторических данных. Кроме того, из-за того, что тюркские народы сохранили в своих геномах корни предков ССМ, мы смогли провести датирование примесей, и предполагаемые даты находятся в хорошем согласии с историческим периодом тюркских миграций и перекрытием экспансии монголов. Наконец, многое еще предстоит узнать о демографических последствиях этого сложного исторического события, а дальнейшие исследования позволят распутать многочисленные сигналы о примеси в геноме человека и мелкомасштабное картирование географического происхождения отдельных хромосомных трактов.
VVV Материалы и методы
Заявление об этике
Все субъекты подписали персональные информированные согласия, а этические комитеты участвующих учреждений одобрили исследование.
Образцы, генотипирование и контроль качества
В целом, 322 человека из 38 популяций были генотипированы на разных массивах SNP Illumina (все нацелены на> 500 000 SNP) в соответствии с спецификациями производителей. Наши данные были объединены с опубликованными данными Li et al. [20], Rasmussen et al. [21], Behar et al. [22], Юнусбаев и др. [15], Metspalu et al. [29], Федорова и др. [23], Raghavan et al. [41], Behar et al. [42], и охватили все тюркоязычные популяции (373 человека из 22 образцов) из ключевых регионов по всей Евразии и их географических соседей (см. Подробности об источнике выборки в таблице S1). Лица с более чем 1,5% отсутствующих генотипов были удалены из комбинированного набора данных. Сохранены только маркеры с 97% -ой частотой генотипирования и меньшей частотой аллелей (MAF)> 1%. Отсутствие криптической связности, соответствующей родственникам первой и второй степени в нашем наборе данных, было подтверждено с помощью King [43]. Этапы фильтрации привели <b>к набору данных из 1444 человек, оставшихся для последующего анализа. Важно отметить, что в нашем наборе данных имеется 315224 SNP, которые являются общими для Human1M-Duo и 650k, 610k и 550k Illumina BeadChips. Различные анализы имеют разные требования к плотности маркеров, и поэтому мы подготовили два набора данных. Для приложений проводились трехпольные испытания и ALDER-анализы, требующие минимального фонового LD, обрезание LD на объединенном наборе данных 1M-Duo и 650k, 610k и 550k. Набор маркеров был разрежен путем исключения SNP в сильном LD (парная генотипическая корреляция r2> 0,4) в окне 1000 SNP, сдвигая окно на 150 SNP за раз. Это привело к набору данных 174 187 SNP. Был подготовлен еще один набор данных с плотным маркером для совместного использования IBD и анализа вейвлет-преобразований для датирования вейвлет-преобразований. Для этого были исключены генотипированные образцы 1M-Duo (таблица S1), чтобы увеличить перекрытие SNP среди оставшихся образцов до 515 841 маркеров. Генетические расстояния между SNPs в centiMorgans были включены с генетической карты, созданной проектом HapMap [44]. (далее предоставляю свободу изучать статью самостоятельно)
Приступим.
После фильтрации (соответственно цели исследования) набора данных осталось 1444 человека. Согласитесь, что 373 тюркоязычные особи никак не равны 1444 человекам.
Откуда набрались недостающие? Из ранее полученных данных (образцов). Это указано в статье:
"Наши данные были объединены с опубликованными данными Li et al. [20], Rasmussen et al. [21], Behar et al. [22], Юнусбаев и др. [15], Metspalu et al. [29], Федорова и др. [23], Raghavan et al. [41], Behar et al. [42], и охватили все тюркоязычные популяции (373 человека из 22 образцов) из ключевых регионов по всей Евразии и их географических соседей (см. Подробности об источнике выборки в таблице S1)."
А где именно располагаются популяции тюркоязычные и нетюркоязычные (географические соседи), смотрим на рисунке №1.
В самой статье также говорится, что генетически тюркоязычные популяции отличаются от нетюркоязычных своих соседей "длинными цепочками", которые родом из ССМ (современной Южной Сибири и Монголии). То есть, дополнительная генетика и тюркоязычие связаны друг с другом. Отуречились местные жители в результате генетического вливания. И время этого события тоже в статье указано.
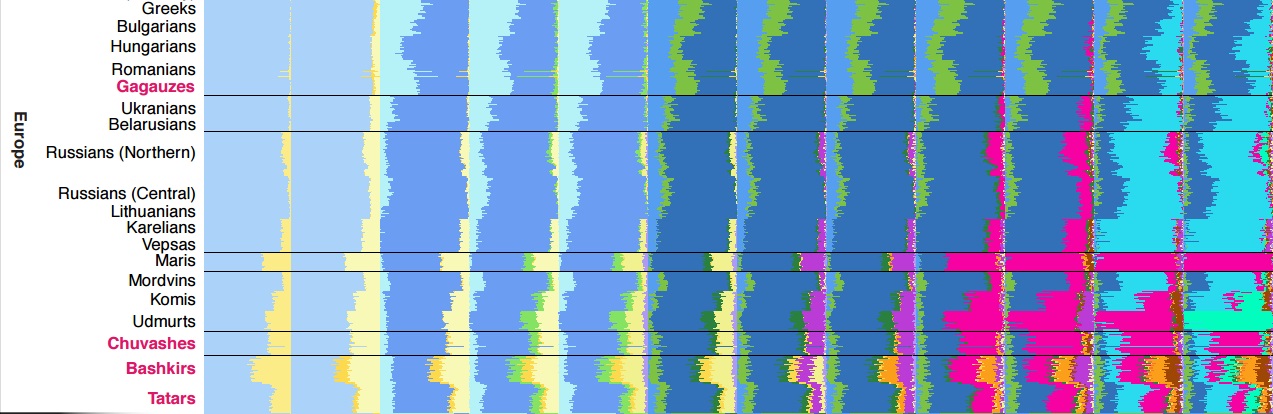
на рисунке тюркоязычные этносы (их название) указаны красным цветом шрифта. Остальные - чёрным. Это и есть "соседи". Из рисунка видно, что татаро-монгольскую составляющую (розовая краска) имеют и не тюркоязычные. Это может означать только одно - культуру тюрков и их язык не приняли.
Вопрос был задан здесь: https://cont.ws/@metafor/54840...
Произвожу эту разборку здесь с той целью, чтобы более подобными разборами текстов не заниматься с нежелающими вникать самостоятельно.

Ну и шкеты нынче пошли... -)



Оценили 11 человек
24 кармы