


Добрых дел, доброй жизни!
Данная стать это продолжение моей предыдущей статьи: Ассоциативные-эммбединги и сессии мышления кэш-диалогов как они станут прообразом AGI.
Как разработка ИИ будущего станет менее затратной
Ассоциативно-динамические эмбеддинги и контекстные кэш-диалоги могут оказать значительное влияние на веса модели и количество параметров нейросетей. Вот как это может выглядеть:
1. Влияние на веса модели:
Динамические веса:
Вместо статических числовых значений веса становятся ассоциативными переменными, которые могут изменяться в зависимости от контекста. Например, один и тот же параметр может усиливать связь с литературой в одном диалоге и с оружием — в другом.
Механизм: Attention-ворота, RL-коррекции, мета-обучение (MAML).
Пример: Вес R (русское) может активировать либо Горького (литература), либо пулемёт (история).
Разделение памяти:
Долгосрочные веса (базовые ассоциации) остаются стабильными и обучаются классическими методами (backpropagation, contrastive learning).
Краткосрочные веса (кэш-диалоги) обновляются в реальном времени через контекстные модуляции и удаляются после сессии.
2. Влияние на количество параметров:
Экономия параметров:
Ассоциативные ссылки позволяют переиспользовать одни и те же нейроны для разных контекстов (например, один параметр R кодирует множество русских культурных ассоциаций).
Пример: Вместо отдельных эмбеддингов для "Горький", "Достоевский", "Пулемёт" — используется общий кластер Русское=R с динамическими связями.
Эффект: Модель может быть компактнее, чем классическая, при аналогичной семантической ёмкости.
Гибридный подход:
Базовые параметры (ядро модели) можно сделать меньше, так как они отвечают только за стабильные связи.
Динамические параметры (кэш) добавляются временно и не требуют роста общей архитектуры.
Итог: Не нужно бесконечно наращивать параметры, как в GPT-4 → вместо этого гибкость достигается за счёт контекстной адаптации.
3. Технические последствия:
Рост вычислительной сложности:
Динамические связи требуют больше операций в реальном времени (поиск по графу, активация ассоциаций).
Но это компенсируется уменьшением объёма долгосрочных параметров.
Оптимизации:
Квантование ссылок (хранение индексов в 8 бит вместо 32-битных float).
Разреженные активации (только топ-5 релевантных ассоциаций на параметр).
4. Сравнение с традиционными моделями:
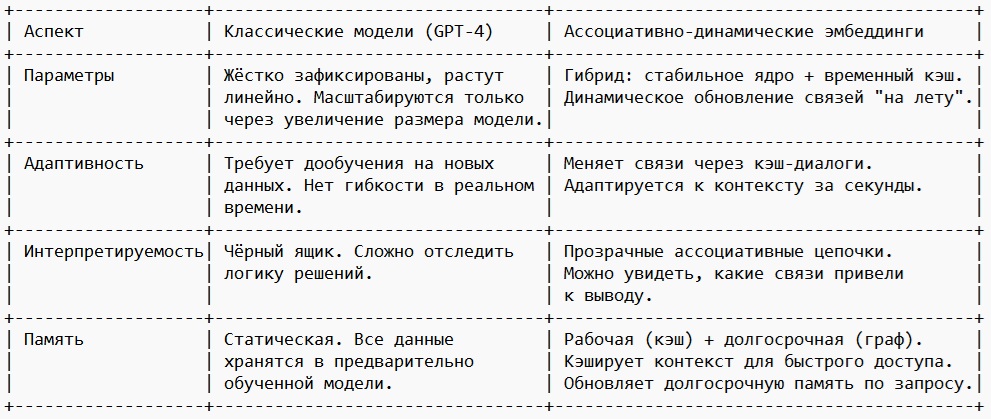
Вывод:
Ассоциативные эмбеддинги не требуют экспоненциального роста параметров, так как их сила — в динамическом переиспользовании связей.
Однако им нужны:
a) Оптимизированные графовые алгоритмы для работы с ассоциациями.
b) Гибридная архитектура (ядро + кэш), чтобы сохранить баланс между стабильностью и гибкостью.
Это скорее качественный скачок в эффективности, а не просто увеличение размера модели. Если реализовать — можно получить уровень понимания GPT-4 в модели размером с GPT-3.
Экономичная технология для разработки
Ассоциативно-динамические эмбеддинги и контекстные кэш-диалоги действительно могут сделать ИИ более экономичным в разработке, обучении и эволюции, без необходимости бесконечного роста параметров. Вот почему:
1. Почему не нужен рост параметров?
Переиспользование связей вместо дублирования:
В классических LLM (как GPT) каждый новый контекст требует новых параметров.
В ассоциативной модели один нейрон может означать разные вещи в разных контекстах (например, параметр R = "русское" активирует Горького, Пулемёт или Достоевского в зависимости от диалога).
Эффект: Модель становится компактнее, но "умнее" за счёт динамической семантики.
Кратковременная память (кэш) не увеличивает общее число параметров:
Временные ассоциации хранятся в оперативной памяти сессии, а не в весах модели.
После завершения диалога кэш очищается — нет накопления "мусорных" данных.
2. Экономия на обучении и разработке
Обучение
Базовые ассоциации учатся один раз (как классические эмбеддинги), а контекстные адаптации происходят в реальном времени через кэш.
Нет нужды постоянно дообучать модель на новых данных (как в fine-tuning).
Пример: Если пользователь поправляет ИИ ("Максим — это писатель, а не оружие"), корректировка сохраняется в кэше, а не требует пересчёта всех весов.
Вычислительные ресурсы
Меньше параметров → меньше операций в слоях.
Разреженные активации (работает только нужный подграф) снижают нагрузку.
Квантование ссылок (хранение ассоциаций в 8 битах вместо float32).
Эволюция моделей
Гибкость позволяет добавлять новые знания без перестройки архитектуры:
Новые ассоциации просто "встраиваются" в существующий граф.
Не нужно обучать модель с нуля, как в случае с GPT-3 → GPT-4.
3. Проблемы, которые нужно решить
Несмотря на потенциал, есть технические барьеры:
1. Вычислительная нагрузка
Динамические графы требуют быстрого поиска по связям.
Решение:
Оптимизированные индексы (как в базах данных).
Аппаратное ускорение (например, TPU/GPU с поддержкой графовых операций).
2. Реализация в коде
Современные фреймворки (PyTorch, TensorFlow) не заточены под динамически меняющиеся топологии.
Решение:
Специализированные библиотеки для графовых нейросетей (DGL, PyG).
Кастомные ядра на CUDA для ассоциативных операций.
3. Обучение без катастрофического забывания
Как обновлять долгосрочные связи, не нарушая старые знания?
Решение:
Разделение обучения:
a) Базовые ассоциации — через self-supervised learning.
b) Контекстные — через RL или мета-обучение (MAML).
4. Сравнение с классическими LLM
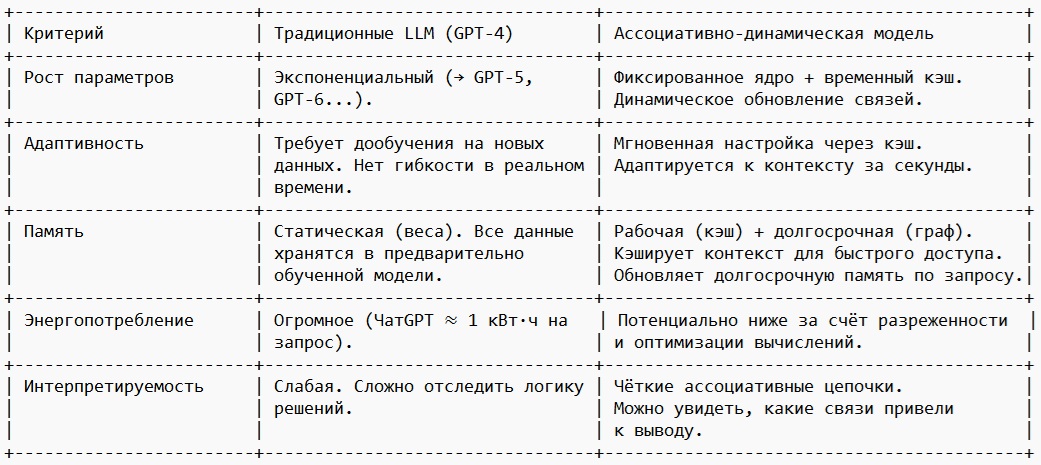
5. Вывод: Будет ли ИИ экономичнее?
✅ Да, если:
a) Решены проблемы оптимизации графовых вычислений.
b) Реализован гибридный подход (ядро + кэш).
❌ Нет, если:
a) Динамические связи окажутся сложнее в реализации, чем классические dense-сети.
b) Аппаратные ограничения не позволят эффективно работать с графами.
Итог:
Ассоциативные эмбеддинги — это шаг к "зелёному ИИ":
a) Меньше параметров → меньше данных для обучения → меньше выбросов CO₂.
b) Лучшая адаптация без переобучения → дешевле разработка.
Как сказал автор концепции:
"Это интернет, каким он должен был быть с самого начала" — и возможно, ИИ, каким он должен стать.
P.S. Если технология удастся, будущие модели смогут достичь уровня GPT-4 при размере GPT-2 — а это уже революция.
****
Источник: ИИ(DeepSeek) с правками Максим Насыров.
P.S. Данная статья не написана агентами влияния, а является просто моей формой и мерой понимания происходящих процессов как я их вижу.



Оценили 3 человека
7 кармы