

академик Андрей Анатольевич Зализняк
Лекция прочитана 5 февраля 2010 года
Продолжение

В прошлый раз, год с небольшим назад, я кое-что рассказывал в этой аудитории об исторической лингвистике. Я много чего хотел тогда вам рассказать, но по времени успел изложить только часть, об остальном сказал совсем бегло. Теперь я воспользуюсь этой возможностью и продолжу то, что собирался рассказывать уже тогда, но что в одну лекцию не укладывается. Немножко повторю и того, что было в прошлый раз, — в качестве напоминания.
Напомню, что в первой лекции мы довольно долго с вами разговаривали о понятии древности языков, древности их названий, о том, существует ли или нет разница языков по древности, — повторять этого не буду.
Самое существенное, что в прошлый раз было рассказано, — это положение, согласно которому все языки меняются, ни один язык не остается неизменным на протяжении времени. И изменения эти, по крайней мере, в том, что касается фонетики языка, подчинены определенным закономерностям.
Главная из них состоит в том, что фонетические изменения не индивидуальны для какого-то одного слова или одного предложения, а если они происходят, то происходят в качестве регулярного изменения некоторой фонемы, которое охватывает уже все слова, где эта фонема встречается. Т. е. если в каком-то слове в ходе истории языка, допустим, о без ударения изменяется в а, то это не может быть ограничено одним этим словом. Это может быть только общее изменение всех имеющихся в языке случаев, когда о оказалось в положении без ударения; а именно, в этом положении оно начинает произноситься как а. Это важнейший для истории всех языков принцип, и я надеюсь, что я могу далее исходить из него как из чего-то достигнутого, потому что остальное в значительной степени выводится именно из него.
А сейчас мы поговорим о более конкретных вещах, и нам придется постоянно использовать этот принцип, но речь пойдет уже о частных его проявлениях.
Сперва такой более общий вопрос: откуда вообще лингвисты знают что бы то ни было о прежнем состоянии языка или языков? Жизнь человеческая коротка, это просто миг по сравнению с тем временем, сколько живет язык; и то, что человек может непосредственно наблюдать, пока он живет, — это очень ничтожная часть истории языка. А увидеть и узнать, как это было 200 лет назад, 300 лет назад, тысячу и две тысячи лет назад, — никаких прямых возможностей у нас нет. Тем не менее, современные лингвисты немало знают о том, как выглядел конкретный язык: русский, французский и т. д. — раньше, чем появилось то реальное звучание, которое мы сейчас можем слышать.
Какие здесь пути? Вот я их назову. Первый, логически самый простой, основан на том, что если речь идет о таком языке, где давно имеется письменность, то остаются письменные свидетельства предыдущих эпох. Ну, на самом деле, следует понимать, конечно, что громадное большинство языков до сих пор остаются бесписьменными, а если взять положение еще, скажем, на 200 лет раньше, тогда часть письменных языков в общем количестве языков мира была совсем ничтожна. Но всё же сейчас уже существует достаточно большое количество языков с письменной традицией. Эту письменную традицию можно измерять в годах. Есть младописьменные языки, в которых письменность введена не слишком давно, скажем, лет 200 назад. Еще более младописьменные, в которых письменность введена 50 лет назад и так далее. Но есть старописьменные языки, где традиция уходит в глубь веков. Русский язык принадлежит, конечно, к числу старописьменных языков, где письменная традиция насчитывает примерно тысячу лет. Есть и более длинные традиции, скажем, традиция английского языка несколько больше. То же верно для французского языка, а, скажем, традиция китайского языка насчитывает более трех тысяч лет.
В таком случае, если речь идет о языке, где документы прежней письменности в какой-то степени сохранились, первый и самый простой источник знания о том, как выглядел язык раньше, — это чтение этих текстов. Текстов, из которых вы увидите, что язык был немного не такой, иногда сильно не такой или совсем не такой, но, тем не менее, это явно предыдущая стадия развития нынешнего языка.
Мы уже говорили в прошлый раз о том, что степень различия между современным языком и тем же языком тысячу лет назад для разных языков оказывается очень неодинакова. Скажем, английский язык за эту тысячу лет изменился так сильно, что нынешнему англичанину читать текст Х века без подготовки практически невозможно — он очень мало там поймет. Точно так же и вы, если вы английским языком занимались и вам дать текст Х века, то, может быть, вы даже не опознаете, что это древнеанглийский, а не какой-то другой язык — настолько сильна степень эволюции этого языка.
В отличие от него, скажем, русский язык изменился гораздо меньше за тысячу лет. Если перед вами будет древнерусский текст XI века, то он, конечно, вам будет труден, во многом непонятен, но все-таки вы прекрасно опознаете, что это тоже ваш язык, только гораздо более архаичный, чем сейчас. Что-то вы поймете, что-то не поймете, но разница так или иначе окажется гораздо меньше.
Такого рода различия можно наблюдать по всему миру. Одинаковым для всех остается то, что различие будет обязательно, только для одних языков оно будет больше, а для других меньше. Анализируя древние тексты (естественно, не с первого раза, когда вы раскрыли рукопись Х века, а, может быть, после долгих годов изучения), вы постепенно доходите до понимания тонкостей языка той эпохи и можете сравнивать его с современным. И можете, в частности, убедиться в том, что какие-то слова произносились заведомо не так, как сейчас.
Но, заметьте, это не такая уж простая задача, даже когда перед вами лежит совершенно читаемый текст, написанный тем же алфавитом, что ныне, допустим, латинским алфавитом для древнеанглийского языка или кириллическим — для древнерусского. Из того, что там написано, еще вовсе не так очевидно, как это читалось. Это тоже целая специальная дисциплина, имеющая, как всякая наука, свои приемы и свой опыт, которые позволяют делать более или менее достоверные выводы о том, что стоит с точки зрения фонетики за такой-то буквенной записью. Повторяю: это требует некоторой специальной тренировки и специального углубления в данную проблему. Но всё же это безусловно доступный для лингвистов материал. Они могут, анализируя письменные тексты прежних эпох, прийти к достаточно правдоподобным или даже вполне надежным выводам о том, как это произносилось. Ну, и тем самым убедиться, что масса слов произносилась не так, как сейчас. И далее уже устанавливать разницу между древним произношением и новым, искать объяснения, каким образом и в каком направлении могли произойти изменения древнего произношения.
Таков, повторяю, логически самый простой способ, и для лингвиста, изучающего соответствующий язык, это счастливая ситуация, когда он есть. Русский язык находится, к счастью, как раз в таком положении: для русского языка традиция письменных документов за последнюю тысячу лет не прерывалась никогда, и с каждым следующим веком документов накапливалось всё больше и больше. Правда, от первых веков письменности на Руси, а именно XI–XII вв., осталось немного документов, но всё же достаточно, чтобы мы составили некоторое первоначальное представление о том, как что произносилось.
Заметьте, это не закрытый фонд! Иногда бывает, что фонд такого рода пополняется, и как раз для истории русского языка в течение последнего 50-летия такое пополнение произошло. Вы о нем слышали, конечно — это открытие берестяных грамот в Новгороде и других местах. Тексты стали появляться из-под земли, их всё больше и больше — сейчас уже около 1000, и они относятся к древнейшим векам истории русского языка и тем самым расширяют наше представление о том, каков был русский язык XI, XII и т. д. веков. Открытие берестяных грамот продолжается, это такая живая вещь — в ней могут быть и новости.
Итак, это простой способ, но ограниченный только теми немногими языками мира, где есть письменная традиция. Повторяю: для большинства языков это не так — письменной традиции нет. В этом случае вы можете подробно записывать, как что звучит, как строятся фразы и т. д., но только в современном состоянии языка.
Как же быть в тех случаях, когда перед вами язык, где письменной традиции нет, т. е. этот простой источник знаний о прошлом отсутствует? Верно ли, что в этом случае мы ничего не знаем о прежних состояниях языка? Нет, неверно. Современная лингвистика умеет и в этих случаях получать определенную сумму знаний о прежних состояниях языка.
Каким образом это возможно? Есть два основных метода, с помощью которых такие сведения могут быть получены.
Один — это так называемый метод внутренней реконструкции. Реконструкция — это восстановление, попытка восстановить прежнее состояние с помощью каких-то логических умозаключений. А слово внутренняя означает, что это будет делаться внутри данного языка, без выхода за его пределы.
Проиллюстрирую некоторые возможности такого рода для русского языка.
Представим себе на минуту — хоть это на самом деле не так — что никакой традиции письменного русского языка нет, что нет не только письменности древних веков, но даже и письменности до 1917 года. Есть только то, что мы сейчас слышим в собственной речи и читаем в том, что только что напечатано.
Возьмем существительные женского рода, скажем, пчела, стена, цена, жена, стрела, весна, десна и так далее. Вот такой ряд. Что у них общее?
– Окончание а.
– Совершенно верно. Еще что-нибудь?
– Два слога.
– Еще!
– е.
– е, конечно! Совершенно верно. Я вам уже сказал, что возьму слова женского рода, так что окончание -а — просто следствие этого. А особенность этих слов состоит в том, что у них всех в корне е.
Можно и продолжить этот ряд: допустим, сестра, метла и так далее.
Вот нас как раз это е и будет интересовать. В произношении совершенно одинаковое е, не правда ли? Невозможно на слух определить, что в одном слове е какого-то одного типа, а в другом случае — какого-то другого типа.
Однако есть основания подозревать, что сейчас е везде одинаковое, а когда-то было неодинаковое. Почему? А вот вы попробуйте, используя свое задаром у вас имеющееся знание русского языка, для всех этих слов образовать множественное число.
– пчёлы, стены, цены, жёны, стрелы, вёсны, дёсны...
– Нетрудно, правда?
– сёстры, мётлы.
– Хорошо. Образовали множественное число. И вам не кажется, что что-то неожиданное происходит с вашими е? Что же с ними происходит?
– Они становятся ударными и некоторые, когда становятся ударными, заменяются на ё...
– Совершенно верно. А некоторые не заменяются. Именно так. Вы это для себя произнесли, и стало ясно, что будет то одно, то другое: пчёлы, но стены; цены, но жёны; стрелы, но вёсны, дёсны, сёстры, мётлы. Иногда происходит замена е на ё, а иногда е сохраняется.
Как это может быть с точки зрения истории, если мы уже знаем принцип, что изменение должно быть одинаковым для одной и той же фонемы? Мы видим, что при переходе от этих исходных форм к множественному числу ударение меняется, и под этим новым ударением некоторые е переходят в ё. Некоторые, но не все, то есть происходит нарушение того главного закона, о котором мы говорили раньше: если есть какое-то фонетическое изменение, то оно должно происходить во всех случаях, когда выступает данная фонема. Ну вот, я готов вам предложить подумать: что же тогда, какое может быть предположение о том, что здесь было на самом деле?
Лев Козлов (8 класс): Ну, там, где во множественном числе ё, раньше было «ять».
А. А. Зализняк: Ну вот, тут вы проявляете свою образованность, вы уже знаете про «ять». Это неплохо — я не против образованности, это даже очень хорошо, но тем не менее сейчас мне хотелось бы услышать рассуждения тех, кто про «ять» не знает, а тем не менее наблюдает за этой ситуацией. Я еще раз хочу сказать, что нисколько не принижаю ценность прямого знания, но и тех, у кого этого знания нет, приглашаю убедиться, что к такому же выводу можно прийти путем собственного размышления.
Главный закон фонетического развития, о котором шла речь, утверждает, что если фонема во что-то изменяется, то она изменяется не в одном слове, не в двух и не в трех словах, и не в половине слов, а во ВСЕХ словах, где она содержится.
В данном случае единственная возможность «уложиться» в этот закон, т. е. избежать его нарушения — это предположить, что у нас здесь не одно е, а когда-то было два разных. Понимаете? Никаким другим способом выйти из этой ситуации вы не можете: если предполагать, что здесь всегда было одинаковое е, то перед вами вопиющее нарушение главного закона развития языка. Отсюда необходимость предположить, что когда-то было два разных е: одно — которое при переходе на него ударения давало ё, а другое — которое при переходе на него ударения давало е. Обозначим их так: е1 и е2.
Это и есть типовой шаг внутренней реконструкции. В чем достижение нашей реконструкции? В том, что мы видели нечто в современном состоянии совершенно однотипное — все эти слова в современном языке представляют собой однородный ряд, — а пришли к представлению, что когда-то раньше это был неоднородный ряд. Это был ряд, в котором в некоторых случаях была гласная е первого типа, а в других случаях гласная е второго типа.
Сразу отмечу, и это существенно: я ведь ничего не сказал о том, что одно е, допустим, какое-нибудь долгое, а другое краткое, или одно более широкое, а другое узкое, одно е с одной фонетической особенностью, другое — с другой фонетической особенностью. Это нам неизвестно. Единственное, что известно — это, так сказать, чистая алгебра — что эти е1 и е2 были не равны между собой. Это важнейшее положение лингвистической реконструкции. А в чем реально они фонетически различались, из этого метода никаким образом не вытекает. Об этом можно строить отдельные гипотезы, но они будут лежать в совершенно другой области. Главный вывод из нашего рассуждения: то, что здесь ныне одинаково, когда-то было различным.
Ну, в данном случае я построил искусственный пример, потребовав от вас, чтобы вы забыли о существовании русской письменности до 1917 года. Потому что, если вы это вспомните, то всё то, к чему мы пришли, будет просто лежать на поверхности. В традиционной графике нашему е1 соответствует буква е, а нашему е2 соответствует буква ять — только и всего.
Так что ответ действительно заключается в яте, это совершенно правильно. И тут я готов апеллировать к вашей образованности: какое из них е, а какое ять? То, которое дает во множественном числе е, или то, которое дает ё? Какое из них в современном языке дает е?
– Ять.
– Верно, ять дает е. Так что, если угодно, более «е-образно», т.е. более постоянно связано со звучанием е как раз ять. Тогда как древнее е под ударением звучит уже не как е, а как ё.
У лингвистов имеются и некоторые высоковероятные гипотезы о том, как фонетически различались древние е и ять, но я не хочу сейчас об этом говорить, потому что это не вытекает из рассматриваемого нами метода.
Напишу вам еще один ряд слов — и на этот раз даже не буду вас особенно приглашать забывать русскую письменность до 1917 года. Можете вспоминать — всё равно это вам не поможет.
Запишу, скажем, такие слова: лоб, боб, моток, поток, песок, исток, листок. Можно и продолжить, но хватит и этого. Что общего у этих слов?
– о.
– Ну вот, вы быстро научаетесь. То было ради е, это — ради о. Давайте займемся исследованием этого о. Опять-таки нет никаких сомнений, что сейчас это совершенно одинаковое о, что вы одинаково произносите лоб и боб, песок и моток и проч. И теперь я вам задам уже такой вопрос: а нет ли у вас каких-то подозрений относительно чего-то, что сейчас одинаково, а когда-то было неодинаковым? Подумайте.
– В родительном падеже где-то о останется, а где-то нет ...
– Верно. Действительно, поупражняйтесь: поставьте всё в родительный падеж и посмотрите, что получится.
– лба, боба, мотка, потока, песка, истока, листка.
– Совершенно правильно, вы очень быстро это замечаете. Оказывается, что слова эти распадаются на две группы — примерно так же, как в предыдущем примере. Здесь другой немножко эффект, но для нас важно, есть разница или нет. Она есть. У нас две группы слов: в одной о сохраняется, в другой выпадает. Вас учили, наверное, что это называется беглое о, верно?
– Да.
– Так что сама ситуация вам знакома. Но когда говорится «беглое о», то имеется в виду, что это тоже о. Понимаете? Но в таком случае мы снова находимся перед лицом нарушения основной закономерности. Оказывается, что после перевода слова в родительный падеж и добавления окончания -а родительного падежа, у вас иногда о остается, а иногда исчезает. Но согласно основной закономерности, если первоначально в этих словах была одна и та же фонема о, то с ней должны были происходить одинаковые изменения во всех словах. А здесь получается, что не во всех: в половине они происходят, а в другой половине не происходят.
Следовательно, методом внутренней реконструкции мы получаем тот же вывод, что и в первом примере: в древности было не одно о, а два разных — о1 и о2. Опять-таки, чем они отличались, мы нисколько пока еще судить не можем, мы достигли только важного вывода о том, что было два разных о, то есть в древности здесь были разные фонемы. И тут, повторяю, дореволюционная орфография вам не поможет: она предусматривает точно такое же одинаковое о.
Помогла бы вам орфография XI века. Если бы вы спустились так глубоко в историю русского языка, что взяли бы эти слова из памятников X века, то оказалось бы, что там они записаны по-разному. Причем разные написания в точности соответствовали бы различию между о1 и о2. Но вот хватит ли вашей образованности, чтобы сказать, что там было? В первом примере был ять, а тут что?
– Мне кажется, что там где о беглое, там была омега.
– Это изящная гипотеза, но в данном случае она неверна. Какие еще есть предположения?
Е. Б. Феклистова (учитель русского языка): Ер!
А. А. Зализняк: Ну, зачем же вы не даете сказать детям?
Тогда я эти слова возьму и перепишу в орфографии XI века. Во-первых, там будет ер на конце — это я подпишу механически — то, что мы сейчас называем твердый знак. Но, кроме того, кое что изменится и в корне.
Давайте условимся: если о остается, то это будет о1, а если падает, то о2. Вы мне сперва продиктуйте слова с о2, а я их подчеркну.
– Лоб, песок, моток, листок...
А вот наш ряд слов в записи ХI века:
лъбъ, бобъ, мотъкъ, потокъ, пúсъкъ, истокъ, листъкъ.
Как видите, нашему о1 здесь соответствует буква о, а нашему о2 — буква ъ.
В данном случае мы имеем возможность действовать двумя методами одновременно, т. е. сперва построить гипотезу методом внутренней реконструкции, а потом еще ее сверить с тем, что дает изучение древних рукописей. И оказывается, что они между собой прекрасно согласуются — действительно это были две разные фонемы: одна была фонема о, а другая была фонема, которую вы сейчас и произнести не можете. Как вы произнесете твердый знак? В современном русском языке считается, что это не что-то произносимое, а всего лишь условный знак для чтения соседних букв. Но в древности это было не так. Это была гласная буква, обозначавшая определенный звук. Сейчас мы не очень точно умеем его воспроизводить; по-видимому, он сохранился в некоторых других славянских языках. Можно предполагать, что он произносился как нечто типа [ə]. Так или иначе, он произносился не как о, и эти фонемы прекрасно различались — так же, как мы сейчас различаем о и а, о и у.
Проверкой нам в данном случае послужило обращение к памятникам XI века. А сама техника внутренней реконструкции не требовала никакого обращения ни к чему, кроме современного русского материала, а именно, кроме констатации того, что в современном русском языке некоторые о всегда сохраняются, а некоторые другие о в определенных условиях выпадают.
Вот вам иллюстрация метода внутренней реконструкции. Как вы понимаете, это прекрасно возможно для языков, у которых никакой письменной традиции нет. Тем самым возможности этого метода гораздо шире, чем у простого обращения к памятникам.
– Скажите, пожалуйста, а они произносили на месте этого твердого знака букву о?
– Гласную. Они произносили гласную, но не о, а некоторую другую, которой сейчас в русском языке нет как таковой. Сейчас ее можно попробовать гипотетически воспроизвести, но это уже другой разговор. Важно то, что это была гласная, она давала лишний слог. Число гласных фонем было больше, чем в современном русском языке. В современном языке их только пять, а тогда было больше.
Теперь рассмотрим второй и самый мощный метод восстановления древней истории языков — сравнительно-исторический метод. В отличие от внутренней реконструкции, здесь фигурирует слово «сравнительный», потому что привлекаются к сравнению два или более языка. И выводы о более древнем состоянии делаются уже на основании сопоставления данных этих двух или большего числа языков. Для этого, конечно, языки должны быть родственны между собой.
Что такое родственные языки? Это языки, которые исторически развились из когда-то существовавшего единого предка. Когда-то — это может быть очень давно, но может быть и не слишком давно. Затем происходит некоторое самостоятельное развитие его наследников: на одной части территории появляются одни новые особенности, на другой — другие; и вот на месте одного древнего — уже два языка. Это основная простейшая схема, так называемая схема родословного древа. Она немного упрощает реальные события, взятые в полном масштабе, но, грубо говоря, она верна. Скажем, для русского, украинского и белорусского языков такой единый язык восстанавливается на исторически небольшом отрезке — порядка 1000 лет. Это для истории совсем маленький отрезок. Если, скажем, искать единый предок для русского и английского языков, то получится уже не 1000 лет, а порядка 7000. И так далее. Но так или иначе, это родственные языки, хотя и с разными степенями родства. Между русским и украинским, русским и белорусским очень близкое родство, между русским и английским родство уже достаточно отдаленное. Но оно имеется.
Итак, для сравнения привлекаются только родственные языки, и в них находятся соответствующие друг другу слова. Как правило, они выглядят не совсем одинаково.
Рассмотрим некоторые русские слова на фоне родственных славянских. Возьмем, скажем, болгарский, сербский, словенский и польский. Это не все славянские языки, но пока достаточно. И давайте посмотрим, как выглядели кое-какие слова, сравнение которых позволяет продемонстрировать, как работает сравнительно-исторический метод.
Возьмем русское слово сон. По-польски это будет sen, по-сербски сан. По-словенски это будет нечто с гласной, которая характерна для словенского языка и для которой в транскрипции используют знак ə: sən. В болгарском будет гласная, характерная именно для этого языка, записываемая буквой ъ: сън. Как видите, все пять языков дают разный эффект, то есть у нас нет оснований считать, что именно русское слово сон является прямым наследием древнего произношения.
Для сравнения, однако, совершенно недостаточно выписать одну подобную строчку. Одна такая строчка не гарантирована от случайностей разного рода, от того, что по каким-то индивидуальным, более тонким причинам у вас регулярность не будет соблюдаться. Поэтому, когда лингвисты пользуются данным методом, они настойчиво ищут как можно большее число строк, устроенных таким же образом. Поэтому я тоже — хотя как можно больше я писать не буду, на это никакой доски не хватит — несколько строк еще напишу.
Ну, например, слово рожь. Оказывается, рожь по-польски будет reż, по-сербски раж, по-словенски rəž и по-болгарски ръж. Это вам уже больше нравится?
Возьмем еще какое-нибудь слово, скажем, вошь. По-польски это будет wesz, по-сербски ваш, по-болгарски въш (по-словенски — прочеркну).
Могу еще взять, допустим, слово песок. По-польски это будет piasek, по-сербски есть несколько диалектных вариантов, я напишу самый простой — песак, по-словенски это pesək и по-болгарски пясък.
Итак, мы получили:
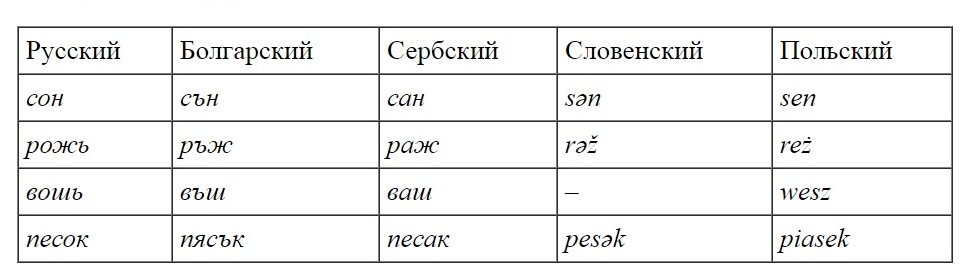
Ну, и, наверное, хватит. Регулярность есть?
– Да.
– Эту таблицу вполне можно продолжить. Таких рядов для близко родственных языков можно насчитать много десятков. Может быть, даже сотен. Я написал вам всего четыре примера, но уже ясно, что это не случайное соответствие: постоянно повторяется набор одних и тех же различий. Получается, что все эти языки между собой различны, совпадений почти нет, но различны они одним и тем же способом, с той же самой регулярностью.
Каким образом можно себе представить, что было в том языке, который является предком всех наших пяти языков? Ясно, что там не было пяти вариантов, там был какой-то один, верно? Если был единый язык, то там был единый способ называть каждый из этих предметов.
Вот это и есть задача для сравнительной реконструкции. Что здесь может быть восстановлено?
Если бы я выписал примеры для слов поток или боб — во всех пяти языках было бы о. В отличие от вот этой разнообразной картины, где представлено пять разных эффектов. Первый главнейший вывод из этого тот же, что мы сделали на основании внутренней реконструкции: то, что дает сейчас одно и то же о во всех сравниваемых языках, и то, что дает вот такое разнообразие, — это были две разных древних единицы — условно о1 и о2. То есть это такой же по сути дела вывод, которого мы достигли на материале одного русского языка.
Но в данном случае мы еще можем примерно понять, что это было фонетически. Мы видим, что разброс в данном случае необыкновенный: по-русски это о, по-сербски — а, по-польски — э, а в двух других языках это какая-то особая фонема, которой в русском языке нет вообще. (Болгарское [ъ] и словенское [ə] фонетически очень близки.)
Что же должен предполагать лингвист, применяющий сравнительно-исторический метод? Он должен предположить, что в древнем языке, предке всех славянских языков, который принято называть праславянским, было две разных фонемы. Одна из них была фонема о, которая дает о во всех пяти языках. Что же касается второй фонемы, которая ведет себя так разнообразно, то тут могут быть разные гипотезы. Но в любом случае необходимо признать следующее.
Понятно, что о здесь исключается, потому что оно уже «занято» первой фонемой. Допустим, вы можете сказать, что это а. Как в сербском. Однако бывает «настоящее» а, бывают слова с таким а, которые дают а во всех пяти языках. Точно так же будут слова, которые во всех пяти языках дают э.
Тем самым предположить, что это было просто о, или просто а, или просто э, невозможно. Мы обязаны предложить какую-то гласную, которая не является ни о, как в русском, ни а, как в сербском, ни э, как в польском. Возможно, однако, что это была такая же гласная, как в тех двух языках, которые дают особую, четвертую гласную, не совпадающую ни с о, ни с э, ни с а.
Так что, конечно, самое вероятное решение — то, что два языка, болгарский и словенский, сохранили эту особую гласную, которая своим особым произношением больше всего похожа на нашу реконструируемую систему, где обязательно должно быть что-то, не совпадающее ни с о, ни с а, ни с э.
Тем самым это сравнение дает нам два вывода. Один вывод, безусловный, — о том, что были две разные единицы: о1 и о2, и второй, предположительный (но с высокой степенью вероятности), о том, что о1 — это в древнем языке было просто о, а о2 — это звук типа болгарского ъ или словенского ə.
Согласны? Вот перед вами иллюстрация того, каким способом мы можем погружаться в глубь истории, приобретать знания о том, как выглядел язык — наш или любой другой — даже в том случае, когда у нас нет никаких литературных памятников, а есть только нынешние данные.
Вот, собственно, то, что на этот раз мне удалось вам рассказать подробнее, чем в первой лекции.
Пойдемте дальше. В ходе истории фонетические изменения в самых разных языках мира часто обнаруживают один и тот же тип тенденций. И самая частая из этих тенденций — сокращение длины слова. Причем почти всегда сокращение начинается с конечной части слова, она оказывается самой уязвимой с этой точки зрения.
В частности, если в языке в некоторый период времени существуют слова с конечными согласными — а таких языков большинство — то есть много шансов, что не пройдет одной-двух тысяч лет, как эти конечные согласные начнут теряться. На протяжении достаточно больших промежутков времени потеря конечных согласных — событие высоковероятное. Скажем, в истории индоевропейских языков практически во всех языковых группах происходили потери конечных согласных — в одних случаях массовые, иногда даже такие, при которых просто 100% конечных согласных отпало. В других случаях эти потери были не такими радикальными, что-то отпало, что-то не отпало. К таким умеренным языкам можно отнести древнегреческий: в нем, например, конечное t или d отпадало, но конечное r или s оставалось.
К языкам предельно решительным в этом отношении следует отнести русский. Русский язык потерял все конечные индоевропейские согласные без исключения. Значит, в отношении любой индоевропейской реконструкции вы можете быть уверены, что если слово оканчивается на согласную, то в русском языке этой согласной уже не будет. Русский я здесь беру просто как частный случай, потому что это особенность славянских языков в целом. Тут отпадало и t, и d, и s и всё остальное.
Дальше представим себе, что в языке имеется какое-то количество слов, оканчивающихся на гласную, — а есть языки, в которых каждое слово оканчивается на гласную. Таким, как вы легко понимаете, был праславянский язык после отпадения всех конечных согласных. Верно? Это действительно очень характерный тип фонетического строя языка, когда все слова оканчиваются на гласную, и, как правило, это следствие не чего-нибудь, а массового отпадения конечных согласных.
Но гласные тоже начинают отпадать. Так что практически история языков устроена таким образом, что примерно за 2–3 тысячи лет конечные фонемы исчезают. Правда, гласные, как правило, отпадают не все: отпадение всех без исключения гласных наблюдается довольно редко. Гласные отпадают избирательно. Самая устойчивая к отпадению гласная — это а. Она может сохраняться даже в тех случаях, когда все остальные гласные падают. Самые неустойчивые против отпадения — гласные и и у.
В славянских языках, в частности в русском, мы наблюдаем картину именно этого типа: слова, которые в индоевропейском языке кончались на а (это слова женского рода, например, слово жена), не сильно отличаются от праиндоевропейского gwena. Конечное —а здесь осталось до сих пор. Не так в словах мужского рода, скажем, стол, хлеб и так далее — ну, хлеб слово заимствованное, так что не будем его рассматривать — а вот стол, конечно, древнее слово, и оно имело вид stolos. Сперва в нем исчезла конечная согласная, а затем гласная тоже. В результате сейчас слова мужского рода, которые имели не а, а другую гласную, оканчиваются просто на согласную. Наши 1-е и 2-е склонения с точки зрения истории различаются (в именительном падеже) тем, какая гласная оказалась в конечной позиции. Гласная а выдерживала, остальные не выдерживали.
Подобная картина наблюдалась в самых разных языках мира. Но это явление всё же не обязательное, а лишь статистически вероятное. В разных индоевропейских языках оно наблюдается везде, но с разной интенсивностью. Например, в праиндоевропейском языке слово wlkwos означало волка (я несколько упрощенно пишу). Окончание мужского рода было -оs, в отличие от женского рода, где было -а. И это окончание —оs первоначально было во всех индоевропейских языках, а сейчас оно остается в неизменном виде только в одном — в новогреческом (с измененной гласной — в виде -as — оно сохранилось также в литовском). В древних языках оно прекрасно засвидетельствовано. Например, санскрит его сохраняет относительно хорошо, но это первое тысячелетие до нашей эры, не наша эпоха. В нашу эпоху ни один язык на территории Индии этого уже не сохранил. Все нынешние наследники древнеиндийских языков имеют только остаток, соответствующий начальной части слова и ничего от -оs.
Из других языков, которые что-то от этого окончания сохранили, назовем латынь. Так, в латинском lupus «волк» окончание -us еще мало отличается от первоначального -оs. Но опять-таки, латынь — это 2000 лет назад; ни один современный наследник латыни уже этого окончания не сохраняет. Но есть некоторые вариации: скажем, итальянский еще не потерял гласную — по-итальянски «волк» будет lupo — s уже нет, но о еще есть. Румынский язык дает уже просто lup. А французский, который вам знаком, сумел еще отсечь и р: здесь это [lu] (а в орфографической записи loup конечное р есть просто традиционное написание).
Таким образом, наблюдается совершенно четкая картина такой эволюции в разных языках: первоначально было два элемента, затем в части языков один пропал, остался лишь один; дальше пропали оба; дальше сверх того, может пропасть еще и следующий, т.е. происходит в высшей степени последовательное обрубание конца.
Филипп Хаустов (8 класс): А те слова в русском языке, которые сейчас оканчиваются на ОС, например, колос, у них в окончании было еще одно ОС?
А. А. Зализняк: Конечно. Это было колсос. А ос в слове колос — это часть корня, а не окончание. Возьмите слова волос, колос; при склонении это ос ведь не будет исчезать, а будет колос, колоса, колосу, потому что это не окончание.
Пожалуй, для красоты я вам продемонстрирую яркий пример такого рода. Давайте я вам напишу некоторую индоевропейскую реконструкцию.
Примерно 7 тысяч лет назад существовало слово, которое чуть-чуть условно я запишу вот так: *gwiHwotoH. Вот такое длиннющее слово со значением «жизнь». А дальше я, если только хватит доски, попробую проследить, что с этим словом случилось в одной из ветвей, которая ведет от праиндоевропейского языка к одному из современных. Этим современным пусть будет у нас французский. Как будет жизнь по-французски?
– Vie.
– Так вот, слово vie — прямой наследник этого древнейшего слова. Прямой, буквальный, с совершенно регулярными изменениями каждого звена без всяких нарушений, вполне строгий.
Теперь давайте посмотрим, что с этим древним словом происходит. Вот здесь такой символ Н; как точно это произносилось, лингвисты не знают, но, очевидно, это было что-то типа [x]. В истории языков часто наблюдается такое явление, что если имеется звук типа х или другой звук, близкий к нему по месту образования, то сам этот звук исчезает, а предыдущая гласная удлиняется. Например, вместо аh получается аа. Это типовое изменение, и оно, в частности, представлено здесь, а именно, iH дает ī долгое, оН дает (с изменением качества гласной) ā долгое: *gwīwotā.
Я везде ставлю звездочку, где форма не засвидетельствована письменными памятниками.
Следующий шаг: gw упрощается, и получается вот такая форма: *wīwotā.
Попутно скажу, что если на этом уровне пойти не по линии, которая ведет к французскому, а по той, которая ведет к русскому языку, то вы получаете, как вы думаете, что?
– Живот.
– Живот, конечно. В древнерусском это слово как раз значило «жизнь». Но только это должно быть не живот мужского рода, а такая живота, то есть «живость». Живот мужского рода есть вариант к тому, что первоначально должно было быть женского рода, — так же, как бывает нагота, или долгота, или доброта, была вот такая живота. Как видите, русский язык очень архаичен — русское слово похоже на то, что возникло уже на втором шагу изменений древнейшего слова. А для французского языка нужно шагов пятнадцать.
Следующим будет тот шаг, что вместо w английского типа появляется v французского типа: *vīvotā. Это мы находимся на уровне еще не латыни, а за много веков до первых памятников латыни. Ну, что-нибудь порядка XX века до н. э.
Дальше произойдет изменение безударного о и получится *vīvutā.
Следующий шаг: это u ослабляется до i: *vīvitā. Дальше — потеря v между гласными, т.е. получается *vītā. Те, кто образован в латыни, уже могут кое-что опознать, верно?
– Латинское vita.
– Совершенно верно. Но здесь я всё еще должен оставить это слово под звездочкой.
И, наконец, первый шаг не под звездочкой — это латынь, слово с а кратким на конце: vīta, т. е. именно то, что засвидетельствовано в латыни.
Дальше начинается жизнь языков-наследников латыни. Раннероманская форма — это еще так называемая вульгарная латынь. Это то же самое, только уже нет долготы i в корне: просто vita.
Дальше западнороманское слово, т. е. распространенное в западной части Римского мира, где сформировались потом французский, испанский, португальский языки: vida.
Следующий шаг — галльско-романский язык, распространенный на территории будущей Франции: vide.
Следующий шаг — d ослабляется до звука đ (равного английскому звонкому th): viđe. Это уже первое тысячелетие нашей эры — что-нибудь порядка VI века.
Дальше идет старофранцузский — он теряет этот звук вообще, и получается viе (в произношении два слога: [vi-e]).
И тут уже остается всего один ход. Сколько там всего ходов — посчитайте.
И вот вам французское vie, которое читается как сейчас: [vi].
Так что, как видите, здесь путь совершенно строго состоит из событий, каждое из которых было не единичным, — не только в этом слове, но и во всех словах, имеющих соответствующие фонемы, было всё ровно то же самое.
*gwiНwotoН
*gwīwotā
*wīwotā
*vīvotā
*vīvutā
*vīvitā
*vītā
vīta (классическая латынь)
vita (вульгарная латынь)
vida (западнороманское)
vide (галльско-романское)
*viđe
viе [vie] (старофранцузское)
[vi] (современное французское)
Так что русское живот, точнее живота, является точным соответствием французского vie. Только заметьте, что в русском слове живот французскому v соответствует не в, а ж.
Г. П. Морозова (учитель физики): Можно вопрос?
А. А. Зализняк: Да.
Г. П. Морозова: А чем подтверждены изменения, которые произошли до латыни?
А. А. Зализняк: Чем подтверждены? Да всё теми же методами, о которых я рассказывал очень кратко. Каждый из всех выписанных здесь фонетических переходов представляет собой результат подобного рода умозаключений. Главное здесь то, что каждый из них предложен лингвистами вовсе не на основании (или для объяснения) именно этого конкретного слова, а на основе анализа ВСЕХ слов, где имелось такое же сочетание фонем. А таких слов для каждого шага оказывается необходимым учесть достаточно много, часто много десятков.
Именно этим гарантируется то, что выписанные формулы перехода не являются простой выдумкой, удобной для объяснения данного конкретного слова. Ведь если формула всего лишь случайно удобна для данного слова, а в действительности неверна, то есть реальной истории фонетических изменений не соответствует, то она не даст правильного результата во всех остальных словах, имевших рассматриваемое сочетание фонем. Соответственно, при анализе всей совокупности этих слов лингвист должен будет ее отвергнуть.
Таков здесь ответ в самом общем виде.
Г. П. Морозова: А где тут начинается письменность?
А. А. Зализняк: Граница письменного и неписьменного языка обозначена звездочкой. Звездочкой показаны неписьменные реконструированные состояния. Первый раз я не ставлю звездочку здесь [указывает на латинское vīta], потому что только начиная с этого уровня я могу написать, что это памятники латыни. До этого тут ни одного памятника, естественно, нет. Письменное состояние начинается примерно с III века до н. э. Строго говоря, латинские памятники начинаются с VI века до н. э., но это слово там не встречается, там совсем немного надписей: на браслетах и других предметах. Так что реально латинскую письменность можно учитывать с III века до н. э. Всё предыдущее — вплоть до состояния, бывшего 7 тысяч лет назад — это, естественно, есть результат умственной деятельности лингвистов. Как всякая умственная деятельность, она может приводить и к ошибкам, но существенно то, что это не субъективные догадки, а результат применения достаточно строгих принципов.
Как я вижу, я перетратил время, поэтому я не буду вас развлекать другими примерами, а изложу только одну общую идею, весьма существенную для понимания того, как устроена эволюция языков в большом масштабе.
Я вам подробно рассказал, как неумолимо уменьшается длина слова: сперва отпадают согласные, потом гласные, потом у какого-нибудь loup отпадает еще и последняя согласная корня. Казалось бы, за те 70 с лишним тысяч лет, которые существует язык, все языки должны были свестись к тому, что всё укорачивается до одного звука. Но ничего подобного. Длина фразы с одним и тем же смыслом в самых разных языках мира очень мало колеблется. Вот в финском языке очень длинные слова, а в каком-нибудь другом языке, китайском, например, — очень короткие слова. Вроде бы должна быть огромная разница. На самом деле эта разница будет только если искусственно вычленить отдельное слово. Но надо мерить не слово, а то, сколько времени занимает выражение некоторой мысли, верно? Потому что очень может быть, что слова короткие, а их для выражения мысли требуется в три раза больше. И при таком измерении у вас получается в разных языках примерно одно и то же.
Это видно, если вы сравните какой-то текст на латыни с его переводом, например, на французский. В латыни есть падежи, сложные глагольные формы и так далее. Во французском падежей нет, и, казалось бы, все французские слова гораздо короче. Вы видели: там вместо lupus — loup. Такое ощущение, что французская фраза должна быть гораздо короче, чем латинский перевод. Но в действительности она будет примерно такой же длины. И это будет так же верно для всех других случаев в истории языка.
Да, слова, как таковые, укорачиваются, и это неумолимый процесс во всех языках. Но по мере того, как длина слов уменьшается, какие-то другие элементы языка оказываются компенсирующими, а именно, появляется необходимость вставлять во фразы дополнительные слова. Для французского, например, для выражения родительного падежа потребуется предлог de — а в латыни не надо было никакого de. А во французском вам придется сказать: la ville de Paris; la maison de mon pиre. То же самое и в английском языке, там есть of, которое не требовалось в древнеанглийском, потому что в древнеанглийском был родительный падеж. И дательный падеж там был, так что и to тоже не требовалось.
Дальше происходит то, что все эти падежи теряются. Но надо же как-то выражать те же самые отношения. И вот появляется предлог. А предлог плюс короткое слово — это то же самое по длине, что прежнее длинное слово.
Вот у меня здесь под рукой есть книжечка, где приведена одна и та же фраза Священного Писания на всех тех языках мира, на которые миссионеры успели его перевести. И хорошо видно, что длина этой фразы чрезвычайно мало меняется. На русском языке ее запись составляет 98 букв, на французском — 111, на латыни — 120. И так далее. В каких-то совершенно экзотических языках, например, в новозеландском языке маори –– 108. Длина колеблется незначительно, в пределах 25% — это совершенно несущественно. И можно предполагать, что 10 тысяч лет назад и 20 тысяч лет назад фразы были примерно такой же длины. Всё это время происходили гигантские процессы по усечению слов, но они всегда компенсировались. Этот механизм предусматривает, с одной стороны, усечение длины слов, а с другой стороны, таким же неумолимым образом предусматривает появление новых элементов в масштабах речи как таковой.
Ну, и, пожалуй, я не буду вдаваться в подробности этого процесса, поскольку я немножко превысил время. Давайте на этом остановимся.
(Аплодисменты).
И. Б. Иткин: Уважаемые господа, какие будут вопросы?
Елизавета Щеголькова (8 класс): Вот, допустим, есть племя в Тихом океане. Они никого не знают, их никто не знает, и вот в этом племени есть письменность. И через какое-то время они все вымерли по какой-то причине. А потом туда пришли другие люди и обнаружили их тексты, только тексты, которые уже никто не умеет читать. Можно из этого что-то извлечь и о них узнать?
А. А. Зализняк: Вы придумали проблему, которая кажется самой невероятной и фантастической, а на самом деле она неоднократно вставала перед лингвистами. В таком состоянии до сих пор существуют в мире некоторые записи. Некоторые подобные тексты расшифрованы. Это счастливая часть. А некоторые не расшифрованы до сих пор. Причем немыслимое количество мозгов затрачено на то, чтобы это сделать, но пока что некоторые остаются нерасшифрованными.
Я рекомендую вам книжку Иоганнеса Фридриха «Дешифровка забытых письменностей и языков», в которой приведены изумительные примеры такого рода, и они очень хорошо изложены, и перевод хороший. Парочку примеров я расскажу, потому что это очень интересно.
Ровно в таком состоянии были письмена, которые нашли в большом количестве при археологических раскопках на Крите и в материковой Греции в начале и середине ХХ века. Они были на глиняных таблетках, пластиночках из обожженной глины, иногда на других материалах. В распоряжении ученых оказалось много сотен таких текстов. Это была явно одна и та же письменность, один и тот же набор знаков, порядка 100 разных знаков. И решительно никаких сведений о том, что бы это могло быть. Предельно трудный случай для расшифровки: тексты на неизвестном языке, записанные неизвестным типом письма; и при этом нет билингв (то есть параллельных записей на двух языках). Это так называемое критское линейное (или линеарное) письмо B. В — потому что было и другое письмо, письмо А, но именно письмо В имеет славную историю.
Расшифровка этого письма — замечательный факт в истории лингвистики, не менее славный, чем расшифровка египетской письменности Шампольоном или древнеперсидской Роулинсоном. Основная роль в этом открытии принадлежит английскому архитектору Майклу Вентрису; второй участник — профессор греческой филологии Джон Чедвик. Вентрис составил всеобъемлющую таблицу, приводящую в систему все наблюдаемые последовательности знаков линейного письма В. При этом он убедился, что есть много разных слов, у которых начальные знаки повторяются, но встречаются разные концы. Понимаете, что это был намек на то, что слова склоняются или спрягаются, т. е. основа их постоянна, а меняются окончания. И если какие-то слова имеют одинаковый набор окончаний, значит, они относятся к одному грамматическому классу. Так постепенно удалось установить на чисто «алгебраическом» уровне основные грамматические закономерности текстов, еще не пытаясь разгадать ни единого слова и не зная, что это за язык.
Многие исследователи пытались подставить в эти тексты слова самых разных древних языков, распространенных вокруг острова Крит: египетского, этрусского, языков Палестины, языков Малой Азии. Но всё проваливалось, никакие из этих попыток не были успешны. Что касается греческого языка, то к нему никто не обращался, потому что у археологов господствовала всеобщая полная уверенность, что речь идет о языке культуры, несравненно более древней, чем греческая. Сам Вентрис считал, что тексты написаны на каком-то языке, родственном этрусскому.
Опираясь на статистические закономерности распределения знаков, Вентрис смог установить вероятные фонетические значения нескольких знаков. С их помощью ему удалось выявить в тексте названия некоторых критских городов. И оказалось, что эти названия имеют грамматическое оформление, похожее на греческое. И вот Вентрис, несмотря на всеобщее убеждение, что древнейшее население Крита было не греческим, и на свое собственное мнение, что таблички написаны на языке, близком к этрусскому, решил всё же проверить, что получится, если попытаться подставить в текст греческие слова. И к его изумлению, один за другим стали открываться элементы текста на древнейшем диалекте греческого языка.
Окончательной победой расшифровки можно считать тот день в мае 1953 года, когда Вентрис получил письмо от своего коллеги археолога Блегена, который вел раскопки в Пилосе на Пелопоннесе, с текстом только что найденной новой таблички. Это был некий список, где в конце каждой строки стояло изображение треножника и цифра (написание цифр уже было известно). В строке с цифрой 1 Блеген, используя расшифровку Вентриса, прочел ti-ri-po, в строке с цифрой 2 — ti-ri-po-de. Это прямые соответствия архаического греческого tripos «треножник» (в единственном числе) и tripode (то же в двойственном числе). Несомненную греческую интерпретацию получил и ряд других слов текста.
Сейчас критское линейное письмо В уже расшифровано полностью. Вот вам замечательная счастливая история.
Но есть и истории, напротив, несчастные. Самая главная из них — это история Фестского диска, о которой вы, наверное, слышали. Фестский диск найден тоже, кстати, на Крите, в городе Фест, и нынешние путешественники, которые ездят на Крит купаться в море, могут зайти в знаменитый музей, где выставлен Фестский диск. Это обожженный глиняный диск, размером немного побольше ладони, необычайно красивый, аккуратно исписанный с двух сторон по спирали знаками иероглифического вида. Среди них есть головы, изображения людей, животных, растений, оружия. Но это не рисунки, а настоящее письмо; более того, каждый знак не процарапан, а выдавлен в глине штемпелем — т. е. принцип тот же, что у Гутенберга.
Для Фестского диска существует множество попыток расшифровки. Прочтения предлагались самые разные — от списка городов или кораблей до гимна богам и даже до разнузданного гимна весьма современного, почти неприличного содержания. Но тут, к сожалению, применим очень простой принцип: если некто предлагает полную расшифровку Фестского диска, то ее можно даже не читать. Надежными здесь можно считать только успехи в установлении слогового характера знаков, в изучении закономерностей их распределения и т. п., но не более того.
Так что ситуация, которую вы обрисовали, является — не скажу массовой, — но во всяком случае, многократно повторявшейся в истории изучения языков. Это безумно интересный и такой волнующий раздел лингвистики — расшифровка самой письменности как таковой. Хотите положить на это жизнь — тогда можно чего-то достичь, но просто так сесть и расшифровать к вечеру такую вещь, как многие надеются, — это никому не удавалось.
Лиза Щеголькова: Спасибо.
Филипп Хаустов: После того, как все падежи, склонения-спряжения отпали, окончания «съедены», откуда берутся новые частицы, типа de, of? Какого они происхождения?
А. А. Зализняк: Они берутся из того, что уже было в языке, но использовалось редко. Допустим, в русском языке пропали окончания родительного падежа — чем бы вы их заменили? Например, «дом приятеля», как бы вы сказали, если нет родительного падежа?
Филипп Хаустов: Я имел посещать мой друг вчера.
А. А. Зализняк: Да, но это не родительный падеж. А для родительного падежа какой-нибудь предлог пришлось бы использовать. Какой? Из имеющихся. Ему надо было бы придать немножко более общее значение.
Филипп Хаустов: «У», например...
А. А. Зализняк: «У», может быть. Вот ровно в таком положении оказался болгарский язык, единственный славянский язык, который потерял падежи. В болгарском языке нет окончаний падежей. Что же в этой ситуации пришлось сделать? Пришлось заменить их предлогами, поэтому по-болгарски это будет «дом на мой друг». Конечно, предлог «на» изначально не имел этого значения, оно несколько сдвигается в сторону по сравнению с тем, что было.
И. Б. Иткин: Еще вопросы?
– Меня интересует, насколько правильны выводы по поводу произношения слов, в отношении которых применяется реконструкция. Насколько я понимаю, мы имеем дело с безакцентным произношением только во французском, а всё остальное — с натяжкой.
А. А. Зализняк: Можете называть это натяжкой, если у вас заранее имеется некоторый скепсис. Мы можем говорить о некоторой доле вероятности — это совершенно верно. Звездочкой здесь показано, что это не засвидетельствовано. Для остальных слов орфографическая запись засвидетельствована, а то, что я написал в скобках — это гипотезы лингвистов (в отличие от последнего слова, которое фиксируется, потому что слышится сейчас). Это гипотезы со всеми вытекающими отсюда последствиями.
– В первоисточниках нет записи в транскрипции?
А. А. Зализняк: Нет, само понятие транскрипции — это позднее научное понятие. В древних текстах никакой записи в транскрипции не было.
– А как звучал санскрит?
А. А. Зализняк: Ну, санскрит и сейчас звучит: в городе Бенарес (Варанаси) записали санскрит в качестве родного языка 500 человек.
– А праиндоевропейский?
А. А. Зализняк: О праиндоевропейском можно судить только на основании реконструкции. На самом деле, этот вопрос часто возникает. Строго говоря, лингвист делает вывод только о сходстве, о совпадении и несовпадении: одна фонема в данном случае или две разные. Как звучали фонемы — это всегда гипотеза.
Как правило, в таких случаях основная опора состоит в том, чтобы найти среди живых языков язык примерно такой же структуры и посмотреть, как это звучит там. Языки не слишком разнообразны в этом отношении, не существует языков с какими-то абсолютно другими фонемами. Все языки мира в общем используют некоторый ядерный набор фонем: м, р, а, о, у есть почти везде. И вот подбирается язык, который по крайней мере в этом своем фрагменте максимально близок к тому, что у нас получается по реконструкции. Тогда самым вероятным окажется предположение, что и произношение было такое же, как там. Но, конечно же, это всего лишь гипотеза.
И. Б. Иткин: Еще вопросы?
– Скажите, пожалуйста, а как ученые пришли к выводу, что существовал праиндоевропейский язык, если от него не осталось памятников.
А. А. Зализняк: Пожалуйста. Но это и есть вопрос о том, имеется ли убедительная сила в том, что я вам рассказываю в течение часа и чем занимается большое количество лингвистов в течение двухсот лет.
Первый наблюдаемый вывод состоит в том, что существуют языки, которые очень похожи друг на друга. Не вызывает, например, сомнения то, что русский и украинский языки похожи, и это сходство не случайное. Тем самым мы делаем первый шаг в нашем заключении, что, вероятно, существовал язык-предок, общий для этих двух.
Все следующие шаги строятся таким же образом. Далее идет совокупность русского с украинским, с одной стороны, и, скажем, с другой стороны, совокупность польского с чешским. Вот у вас уже восточнославянские языки и западнославянские языки. Про них вы делаете то же самое предположение, что они в какой-то момент сходились к одному предку.
И вот таким же способом, делая уже не два шага, а три, четыре, шесть, семь, десять шагов вы доходите наконец до понятия праиндоевропейского языка. Вы правы в том смысле, что при каждом следующем углублении возрастает некоторый элемент ненадежности, — это верно. Ваш вопрос вовсе не такой немыслимый. Мне один раз в очень серьезной беседе пришлось отвечать на этот же вопрос, когда я разговаривал с настоящим французским скептиком — из тех, кто желал отрицать лингвистику как таковую. И вопрос был в точности такой же: откуда вы знаете, что существовал праиндоевропейский язык, и не является ли всё это сплошной вашей, лингвистов, выдумкой? Вот примерно это я ему и отвечал. Так что мне не в первый раз приходится отвечать на этот вопрос.
Е. Б. Феклистова: А удалось Вам его убедить?
А. А. Зализняк: О нет, что Вы! Француза-скептика разве убедишь!
И. Б. Иткин: Еще вопросы, господа?
Полина Чернышева (6 класс, школа «Интеллектуал»): Вот тот язык, который вы написали перед старофранцузским — это какой?
А. А. Зализняк: Это тоже старофранцузский, но более ранний, который еще не отражен в записях. Это галльско-романский язык, та форма романской речи, которая бытовала на территории Галлии.
И. Б. Иткин: Есть ли еще вопросы? Если есть, держим руку высоко. Да?
Е. Б. Феклистова: Меня интересует ваше личное отношение, осмысленно или не осмысленно учить в 11 классе к экзамену, какое ударение указано в нормативном словаре?
А. А. Зализняк: Ну, понимаете, поскольку я занимался составлением соответствующих словарей, моя позиция заключается в том, что это осмысленно.
Другое дело, что есть вопрос о том, насколько и что можно и должно навязывать, а насколько нельзя. Сейчас общая тенденция состоит в том, чтобы не соблюдать правила, которые когда-то считались совершенно незыблемыми. Книги выходят с вольной орфографией, во многих издательствах отменена функция редактирования. И то, что сейчас читают школьники, — это часто плохой русский язык, с плохой орфографией и прочим.
Что касается ударений — то тут, конечно, есть разные зоны. Я думаю, что очень хорошим в этом смысле и очень взвешенным, не ударяющимся ни в одну крайность, ни в другую является Орфоэпический словарь Н. А. Еськовой. Там выдержана тонкая градация указаний о том, как относиться к разным ударениям. Для значительной части слов в нем даются одинаково правомочные ударения: есть и такое, и такое, не надо бояться любого из вариантов. Для вариантов немножко различающихся у нее указываются тонкие различия: устаревающий вариант, устаревший вариант, не рекомендуемый вариант (кстати, не рекомендуемый вариант часто означает, что так говорит большинство), неправильный вариант и, наконец, грубо неправильный. Вот грубо неправильного, наверное, стоит избегать. Так что у меня такое ощущение, что такие крайности действительно хорошо было бы устранять в школе, а всё остальное находится уже более или менее в сфере факультативного.
И. Б. Иткин: Какие еще вопросы?
– Как вы считаете, насколько осмысленно было бы искусственно создать синтетический язык для всего человечества?
А. А. Зализняк: Эта идея в какой-то момент очень активно реализовывалась. Была целая эпоха: конец XIX — начало ХХ вв., когда появилось несколько таких языков. Самый известный из них — эсперанто, но есть еще добрый десяток других, менее известных: идо, волапюк, например. Остальные не выжили. Язык эсперанто в какой-то степени выжил, но большого успеха не имел.
Тут проблема вот какая. Доктор Заменгоф, который изобрел эсперанто, хотел создать идеальный язык, который не обладает никакими недостатками языков живых. Из-за этого его стали пропагандировать и предлагать всем им пользоваться.
А какие недостатки у живых языков? Те, что в них содержится масса исключений, масса неправильностей, какие-то сложные склонения, спряжения. А главное, что если какое-то правило есть — то из него обязательно есть исключения. И казалось так, что если устранить этот недостаток естественного развития языков, снабдить человечество искусственным языком — то всё будет идеально. И действительно — эсперанто задумано именно так.
Но постепенно обнаружилось следующее обстоятельство, которое очень сильно влияет на оценку всего подобного творчества. Дело в том, что, как хорошо знает сегодня лингвистика, наличие исключений в языках не является каким-то случайным шумом в устройстве механизма языка. К нему нельзя относиться как к чему-то постороннему по отношению, так сказать, к идеальному замыслу языка. Выяснилось, что наличие исключений в живых, натуральных языках абсолютно неизбежно ввиду изменчивости языка — потому что язык, изменяясь, никогда не меняет свою структуру целиком от начала до конца. Меняются какие-то одни пласты, а другие остаются в более архаичном состоянии. Например, решительно в любом языке, где есть вспомогательные глаголы быть и иметь, они будут спрягаться не так, как стандартные глаголы. Сложнее будут спрягаться, иррационально, и каждую форму придется отдельно запоминать. Это характерно для французского, для английского, для латыни — решительно для всех языков. Казалось бы — зачем это нужно? Пусть у них будет такое же спряжение, как у всех остальных глаголов. Но это происходит не по принципу «зачем», а оттого, что такой употребительный глагол, важнейший для системы, постоянно использующийся, постоянно повторяющийся, превосходящий среднюю частотность других глаголов в сотню раз — изменяется намного медленнее. Спряжение вспомогательных глаголов в громадном большинстве языков отражает состояние на несколько тысяч лет более древнее, чем спряжение рядовых глаголов. И это очень существенно.
Вы, может быть, пока не понимаете, к чему я это говорю, но я, тем не менее, дойду до ответа на ваш вопрос; я как раз к этому подхожу, чтобы ответить более основательно.
Тем самым оказывается, что при нормальном развитии языка как функции общения, а не просто чего-то выдуманного на бумаге, обязательно происходит такое расслоение: в одном языке бывают пласты более современные, средние и древние. У них разная грамматика, и поэтому древнее выглядит как исключение; так и формулируется, что это исключение.
К выдуманному доктором Заменгофом эсперанто это не подходит — там всё идеально. Но дальше происходит одно из двух. Либо это эсперанто остается на полке памятником изобретательности доктора Заменгофа, либо оно становится живым международным языком. А если оно становится живым международным языком, оно никуда не уйдет от законов развития языка: в нем появятся исключения. И тогда человечеству нет уже никакого смысла бросать свой английский, свой испанский, свой русский язык и переходить на эсперанто. Потому что пройдет лет сто (в масштабах развития языка это мелочь, надо только пренебречь тем, что тогда будем уже не мы) — и это эсперанто перестанет быть идеальным языком.
Вот это оказалось главным препятствием. В самом деле, в первой половине ХХ века на эсперанто очень активно переписывалось некоторое количество энтузиастов во всем мире. В одних странах это приветствовалось, в Советском Союзе это преследовалось, но это уже отдельная история. Факт тот, что на эсперанто стали сочинять романы, какие-то стихи писать, и выяснилось, что это до известной степени возможно. Но стали появляться исключения, отклонения от правил, идиоматические (то есть невыводимые из своих элементов) сочетания — ровно по тем же неизбежным законам развития языка, о которых я говорил. Эсперанто стало больше похоже на обыкновенный язык. Оно еще не все свои преимущества потеряло, но находится на том пути, чтобы потерять.
Примерно то же самое происходит с ивритом в Израиле. Там они, правда, и не исходят из того, что это должен быть язык без исключений. Библейский язык, на основе которого построен иврит, — это вполне нормальный язык, в котором имеется регулярная грамматика, но имеются и части совершенно неправильные и т. д. Кстати, пример Израиля показывает, что в принципе возможно создать такую социальную ситуацию, что новое поколение будет говорить на языке, который предложили, так сказать, из идеи и который не был языком родителей. Так что с этой точки зрения эсперанто в принципе могло бы и привиться –– дело здесь, очевидно, в другом.
Вот ответ на вопрос, почему эсперанто реально не достигло статуса конкурента, скажем, для английского языка и, по-видимому, не достигнет. А про остальные тем более нечего сказать.
– У меня еще один вопрос. Может быть, абсурдно такой вопрос ставить, но правомерно ли говорить о том, что в будущем разовьется какой-то совершенный язык, лучше всех прочих языков?
А. А. Зализняк: О чем-то подобном уже шла речь в прошлый раз. Остановлюсь на этом вопросе еще раз, потому что он действительно многих волнует. Речь идет на самом деле о том, существуют ли более высокоорганизованные и более ценно устроенные языки, чем другие.
Ну, того, чего можно достичь в будущем, я не буду касаться, этого я не знаю. Но если сравнивать ныне существующие языки, можно ли одним языкам ставить высокую оценку, а другим низкую по некоторой шкале? Например, по той, которую Вы предлагаете. И оказывается вот что. Если оценивать язык не вообще, а применительно к тому обществу, которое он обслуживает, скажем, папуасский язык — для общества папуасов, язык австралийских аборигенов — для австралийских аборигенов, английский язык — для тех, кто английским как родным пользуется, то оказывается, что степень приспособленности языка к нуждам соответствующего общества во всех случаях одинакова: она хороша. Языков, которые неудовлетворительно обеспечивают потребности своего общества, не наблюдается. Другое дело — если начать папуасский язык применять к английским нуждам. Тут окажется, что не хватает понятий решительно ни для чего.
Что говорить, русского языка оказалось недостаточно, чтобы покрыть все компьютерные и прочие понятия, которые к нам пришли такой массой совсем недавно, на ваших глазах. Когда происходит такое внедрение в жизнь общества чужого языка, то собственный язык этого общества действительно может оказаться в положении, что ему не хватает слов, выражений и прочего. Но причина здесь не в том, что один язык совершеннее другого, а только лишь в разнице и технического и экономического состояния обществ. Не говоря уже о том, что различна природа — у одних пальмы растут, у других плавают тюлени. И помимо этого, бывает разница еще и в другом. Например, выясняется, что ни один язык мира не имеет прямого эквивалента для русского слова тоска... Ну и так далее.
И. Б. Иткин: Ну, давайте тогда последний вопрос.
А. А. Зализняк: Да нет, пусть задают вопросы. Я не против.
Филипп Хаустов (8 класс): Скажите, пожалуйста, а артикль — это достаточно молодое явление в языке?
А. А. Зализняк: В тех языках, история которых хорошо наблюдается, европейских в основном, артикль появляется на глазах истории. В латыни его нет. Но в греческом артикль был. Так что это не значит, что артикль — это во всех языках молодое явление. Греческий имеет артикль с самых древнейших времен — со времен «Илиады». Тут, по-видимому, нет хронологической зависимости. Для европейских языков это понятие последних полутора тысяч лет. Закономерности, которая была бы характерна для всего мира, я не знаю, думаю, что артикли появляются и исчезают примерно так же, как и другие элементы. Нет такого закона, который действовал бы во всех языках. Если бы он был, то во всех современных языках мира был бы артикль.
А как артикли возникают, известно довольно хорошо: это слово со значением «тот» для определенного артикля и со значением «один» для неопределенного — почти всегда это так. Как они могут исчезать? Тут у меня хороших примеров нет. Наверное, они исчезают путем срастания со словом с переосмыслением полученного результата. Т. е. не то, что их просто перестанут употреблять. Они могут срастись с началом слова, к которому относятся, стать его частью. (Кстати, не обязательно с началом, есть же постпозитивные артикли, которые стоят после слова, например, в шведском языке, в албанском.) Тогда полученное слово может потерять статус в плане определенности-неопределенности и использоваться как-то иначе. Вот такой здесь возможен путь, а чтобы они просто перестали употребляться — этого не бывает.
И. Б. Иткин: Если больше вопросов нет, то, давайте поблагодарим Андрея Анатольевича.
(Аплодисменты.)
А. А. Зализняк: Спасибо.
цельнотянуто отсюда, с благодарность к Автору






Оценили 14 человек
25 кармы