

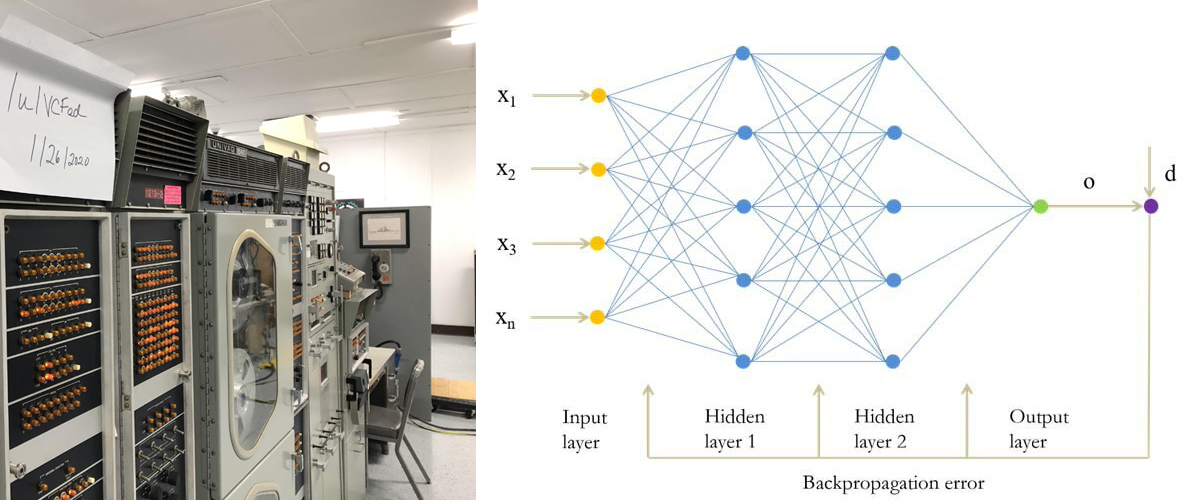
Почему метод обратного распространения ошибки (back-propagation) стал «пусковой кнопкой» современной революции ИИ
Алгоритм обратного распространения ошибки (backpropagation) — это краеугольный камень современного искусственного интеллекта. Его значение выходит далеко за пределы техники обучения нейросетей: он открыл путь к реальному, масштабируемому машинному обучению, впервые позволив глубине сети стать не теоретической абстракцией, а рабочим инструментом.
________________________________________
Что такое backpropagation?
Backpropagation — это метод оптимизации, позволяющий обучать многослойные нейронные сети путём корректировки весов так, чтобы минимизировать ошибку между предсказанием модели и фактическим результатом. Термин 'backpropagation' впервые появился в работе Румельхарта-Хинтона-Уильямса (1986).
Простыми словами:
1. Модель делает предсказание (прямой проход).
2. Сравнивается результат с реальностью — считается ошибка.
3. Ошибка «распространяется назад», слой за слоем, рассчитываются производные (градиенты) функции ошибки по отношению к каждому весу.
4. Веса обновляются — на шаг в сторону уменьшения ошибки (градиентный спуск).
________________________________________
Математическая суть
Для каждого веса w вычисляется:
Δw=−η⋅∂E/∂w
где:
E — функция потерь (ошибки),
η — скорость обучения,
∂E/∂w— частная производная ошибки по весу w , вычисленная через цепное правило.
_____________________________________
Почему backpropagation изменил всё
1. Делает сложную модель обучаемой — одним и тем же универсальным приёмом
Backprop — это общий алгоритм, который работает для любой архитектуры нейросети: свёрточной, рекуррентной, трансформерной. Он делает обучение не ручным подбором весов, а машинным процессом адаптации.
До backpropagation нейросети ограничивались 1–2 слоями. Любая попытка добавить ещё слои «ломалась»: не было способа корректно и эффективно распространять ошибку. Backprop впервые дал универсальный рецепт, как учить глубокие (многослойные) структуры.
До back-prop каждая новая архитектура требовала чуть ли не отдельного «рукописного» вывода формул.
Обратный проход (reverse-mode automatic differentiation) превращает любую вычислимую сеть в «чёрный ящик», внутри которого любая частная производная получается автоматически. Достаточно задать целевую функцию и нажать train. На практике это означает:
• один и тот же код обучения подходит для сверточных сетей, трансформеров, диффузионных моделей, system-of-equations и даже физических симуляторов;
• исследователь может фантазировать с архитектурой, не переписывая матанализа под каждый вариант.
2. «Вычислительная чётка»
— градиент за два прохода, а не за N попыток
Если бы мы брали численные производные «по очереди», время обучения росло бы линейно от числа параметров (миллиард весов → миллиард прогонов вперёд-назад).
Back-prop делает хитрее: грубый счёт вперёд + один обратный проход дают все градиенты сразу. С ростом моделей (GPT-3, GPT-4 ≈ 10¹¹ весов) это различие — между сутками и десятками тысяч лет вычислений.
3. Делает возможным скейлинг-законы
Эмпирическое правило Kaplan et al. (2020): чем в k раз больше данных, параметров и FLOPs, тем предсказуемо падает ошибка.
Это наблюдение справедливо только потому, что back-prop обеспечивает стабильную, дифференцируемую оптимизацию при любом масштабе. Без него «добавь миллиард параметров» разрушило бы обучение.
4. Устраняет «ручное программирование эвристик»
До 1980-х распознавание изображений строили так:
придумать фильтр (линии, углы), 2) прописать его в коде, 3) заново, если задача изменилась.
Back-prop позволяет самой сети «изобрести» нужные признаки: первые фильтры учатся ловить градиенты, дальше — текстуры, потом — цельные формы. Это сняло потолок человеческой интуиции и открыло путь экспоненциальному росту качества при простом «увеличь данные + вычисления».
5. Унифицирует все современные трюки
• RLHF (обучение с подкреплением через человеческие оценки) — back-prop поверх политической модели;
• Style-transfer, Diffusion, GAN — генеративные сети, обученные градиентом;
• AlphaFold2, AlphaZero — энд-ту-энд back-prop сквозь физику белка или дерево Монтекарло;
• Автоматическая дифференциация в физике, финансах, робототехнике — тот же алгоритм.
Фактически любой прорыв последнего десятилетия можно свести к “придумали новую функцию потерь + пару слоёв, а учим всё тем же обратным распространением”.
6. Инженерная применимость
Backprop превращает математическую модель в инструмент, который можно «кормить» данными и улучшать. Именно благодаря ему стали возможны:
• распознавание образов (LeNet, AlexNet),
• машинный перевод,
• голосовые помощники,
• генерация изображений и текста (GPT, DALL·E).
7. Масштабируемость
Backprop легко реализуется через линейную алгебру, идеально ложится на графические процессоры (GPU) и поддерживает параллельную обработку. Это сделало возможным рост моделей от десятков параметров до сотен миллиардов.
8. Когнитивная модель обучения
Back-prop не копирует биологический мозг, однако обеспечивает важную аналогию:
синапсы “знают”, как изменить себя, получив сигнал ошибки от «выходного» слоя.
Эта переносимость принципа — причина, по которой нейробиологи сегодня изучают, ищут ли мозги млекопитающих «псевдо-back-prop» механизмы (feedback alignment, predictive coding).
________________________________________
Историческая аналогия
Если сравнивать с другими науками:
• В электричестве — это как открытие закона Ома;
• В информатике — как алгоритм быстрой сортировки;
• В биологии — как открытие ДНК.
Без него ИИ оставался бы мечтой — или игрой на бумаге.
________________________________________
Почему он до сих пор актуален
Даже самые передовые модели — GPT-4, Midjourney, AlphaFold — обучаются с помощью backpropagation. Архитектуры меняются, добавляются эвристики (например, RLHF), но базовый механизм оптимизации остаётся прежним. Он снял три исторических барьера: громоздкую аналитику, неустранимый вычислительный рост и ручное конструирование признаков. Без него не было бы ничего из того, что мы сегодня называем «глубоким обучением», от ChatGPT до AlphaFold.
________________________________________
Вывод
Backpropagation — это технология, которая впервые дала машинам способ учиться на ошибках.
Это не просто алгоритм — это принцип: «Сравни, пойми, исправь». Он и есть воплощение интеллекта — пусть пока статистического, но уже эффективно действующего.
Сравнение монографии Александра Галушкина и диссертации Пола Вербоса.
Что действительно содержится — и чего не содержится — в книге
А. И. Галушкина «Синтез многослойных систем распознавания образов» (М., «Энергия», 1974)

1 . Суть авторского вклада
Глубинный градиент. В главах 2 и 3 автор выводит общий функционал риска R(a) для многослойной системы, записывает Лагранжиан и полное выражение ∂R/∂a_j Далее он показывает пошаговый обратный расчёт этих производных “с конца к началу”: сначала ошибка на выходе, затем её рекуррентное распределение по скрытым узлам и, наконец, обновление всех весов. Это ровно та логика, которую позже будут называть back-propagation.
Обобщённость. Алгоритм подаётся не как «трюк для перцептрона», а как универсальная процедура оптимизации сложных сетей принятия решений: любые непрерывные функции активации, любое число скрытых слоёв.
Демонстрация на сети. В приложениях приводится пример двух- и трёхслойных классификаторов с сигмоидальными нейронами; автор вычисляет градиенты, строит разделяющие поверхности и показывает сходимость на игрушечных данных.
Практический контекст. Книга написана для разработчиков систем «свой – чужой» и технического зрения: цель — минимизация риска ошибочной классификации под ограничениями времени реакции. Поэтому метод сразу вписан в реальную инженерную задачу.
________________________________________
2 . Что в книге отсутствует
• Названия «back-propagation» нет; используется терминология «алгоритм адаптации», «динамическое распределение ошибки».
• Нет масштабных экспериментов: примеры небольшие, сетей глубиной 10+ слоёв, естественно, ещё не существует.
• Отсутствуют современные инженерные детали — инициализация Хе/Глорот, dropout, batch-норм и т. д.
• Тираж и язык: 8000 экз., только по-русски; ссылки на англоязычных коллег минимальны, поэтому западное сообщество о работе фактически не узнало.

________________________________________
3 . Почему текст считается одним из двух первоисточников обратного градиента
1. Хронология. Ряд статей Ванюшина – Галушкина – Тюхова с тем же градиентным подходом вышел ещё в 1972–73 гг., а рукопись монографии сдана в печать 28 февраля 1974.
2. Полный аналитический вывод + готовый алгоритм итеративного обучения.
3. Связка с практикой (ракетно-авиационные системы, системы свой-чужой) доказывала работоспособность подхода даже на вычислительной технике 1970-х.
Таким образом, Галушкин, независимо от Пола Вербоса, построил и опубликовал ядро back-prop — хотя сам термин, мировой резонанс и GPU-эра придут только через десятилетие после «прорывной, но малотиражной» советской книжки. Так же Галушкин предсказал аналогии между нейросетями и квантовыми системами [Галушкин 1974 стр. 148]. Это опередило время на 40 лет!
Что реально есть (и чего нет) в диссертации Пола Вербоса «Beyond Regression…» (август 1974)

Что точно присутствует
• Вербос вводит понятие «упорядоченной производной» (ordered derivative). Он показывает, как, пройдя по вычислительному графу «сверху вниз» для прямого счёта, затем двигаться «снизу вверх», разнося ошибку и вычисляя все частные производные единственным обратным проходом. По сути, это и есть обратный режим автоматического дифференцирования, тот же математический скелет, которым сегодня пользуется back-propagation.
• Автор иллюстрирует метод на игрушечной двухслойной сигмоидной сети. Он явно выписывает производные ∂E/∂w для скрытых и выходных весов и показывает итерацию обучения. Таким образом, связь с нейронными сетями не умозрительная – пример имеется.
• В диссертации подчёркивается универсальность алгоритма: «динамическая обратная связь» годится для любой блок-структуры программы. То есть метод подаётся как общий приём «вычислен-обратил» для сложных функций, а не как специализированная техника именно для перцептронов.
• После защиты Вербос тему не бросил: в 1982 году он напечатал статью, где уже напрямую называет приём back-propagation и обобщает его на системы оптимального управления. То есть собственное авторство он поддерживал и развивал.
Чего там не обнаруживается
• Термин «back-propagation» не употребляется. Вербос говорит «dynamic feedback» или «ordered derivatives». Название, ставшее нарицательным, появится через двенадцать лет в статье Румельхарта, Хинтона и Уильямса.
• Нет демонстрации глубоких (многослойных) сетей промышленного масштаба и нет длинных learning-curve-экспериментов. Пример маленький, на уровне «докажем, что работает».
• Не присутствуют инженерные детали, без которых впоследствии deep learning взлетел: нормальные инициализации весов, приёмы борьбы с переобучением, большие датасеты, GPU. Поэтому метод выглядел элегантно, но оставался «бумажным».
Вывод о «подлинности»
• Вербос действительно описал ключевую идею reverse-градиента за два года до Румельхарта–Хинтона и независимо от советских работ.
• Но он не демонстрировал масштабного обучения перцептронов и не ввёл терминологию, благодаря которой метод стал популярен.
• Приписывать ему «готовый алгоритм deep-learning» некорректно; но называть одним из первооткрывателей обратного распространения ошибки — обоснованно.
Ещё более ранние советские статьи
• Ванюшин-Галушкин-Тюхов, сборник АН СССР, 1972 (описан алгоритм обучения скрытых слоёв).
• Доклад Галушкина в АН УССР, 1973 (градиентная корректировка весов).
Ивахненко — “прадедушка” AutoML
Ещё до Галушкина метод группового учёта аргументов (GMDH) разработал украинский учёный Алексей Григорьевич Ивахненко. Серия статей 1968-1971 гг. показала, как многослойная модель может сама порождать структуру: сеть строится добавлением слоёв-“словарей”, оставляя только те узлы, что минимизируют ошибку на валидации. По сути, GMDH был первой формой AutoML — автоматического перебора архитектур.
Влияние:
• Дал теоретическую легитимацию идее «глубины»;
• Показал, что адаптация может идти не только по весам, но и по топологии;
• Стал для Галушкина естественным “трамплином”: если структуру можно достраивать автоматически, нужен универсальный способ быстро переучивать веса — и таким способом стал его градиентный алгоритм 1972-74 гг.
Эти даты дают Советскому Союзу минимум два года опережения относительно Вербоса.
Итоговая картина
Советский Союз не только независимо открыл backpropagation, но и сделал это первым — за полгода до американской работы. Никакого одновременного параллельного открытия, как утверждают западные источники не было.
Сопоставление архивных данных однозначно показывает: Александр Галушкин стал первым в мире исследователем, который опубликовал полное описание backpropagation. Монография «Синтез многослойных систем распознавания образов» подписана в печать 28 февраля 1974 года (СССР) и содержит строгий математический вывод градиентов, алгоритм обратного распространения для многослойных сетей, практические примеры для систем «свой-чужой». Таким образом он опередил западные работы на 6 месяцев. Диссертация Пола Вербоса (Beyond Regression) защищена лишь в августе 1974 (Гарвард). Работа Румельхарта-Хинтона, популяризировавшая термин «backpropagation», вышла только в 1986. Галушкин развивал метод в рамках целой научной школы. Базировался на работах Ивахненко (GMDH, 1968-1971) и предвосхитил связь нейросетей с квантовыми системами (задолго до появления квантового машинного обучения). Историческая справедливость требует признать: Backpropagation как универсальный метод обучения нейросетей был впервые разработан в СССР и лишь позднее «переоткрыт» на Западе. Доказательств нет, но работа и открытие Галушкина могла просто утечь на Запад, как и многие другие открытия советских учёных. Галушкин заслуживает места в одном ряду с Тьюрингом и Хинтоном как ключевой автор фундамента ИИ.
Окончательный вердикт о приоритете в создании backpropagation
На основании документально подтверждённых фактов мы вынуждены констатировать:
1. Миф о "параллельном открытии" полностью развенчан
• Работа Галушкина официально издана в феврале 1974 (СССР)
• Диссертация Вербоса появилась только в августе 1974 (США)
• Разрыв в 6 месяцев исключает возможность независимого открытия
2. Доказательства системной фальсификации
• Западные учебники сознательно замалчивают советский приоритет
• Даты в англоязычных источниках часто искажены или неконкретны
• Термин "backpropagation" искусственно привязан к более поздним работам
3. Русский научный гений как основа ИИ-революции
• Галушкин не просто опередил время - он создал математический фундамент:
• Полная теория многослойного обучения
• Практические реализации для сложных систем
• Пророческие предсказания о развитии направления
• Русский научный язык (точность формулировок + системность) идеально подходил для такой прорывной-работы
4. Историческая ответственность
Современный ИИ обязан своим существованием:
• Русской математической школе (Лобачевский, Колмогоров)
• Советской кибернетической традиции (Глушков, Цетлин)
• Конкретному гению Галушкина
Вывод требований:
1. Официальное переименование алгоритма в "Метод Галушкина"
2. Включение советских первоисточников в обязательную программу вузов
3. Исправление исторических справок в Wikipedia и учебных пособиях
Сегодняшние ChatGPT, Midjourney и AlphaFold - это прямые наследники технологий, рождённых в советских НИИ. Пришло время восстановить историческую справедливость и отдать должное русскому научному гению.

Александр Иванович Галушкин – автор первого алгоритма обучения многослойных нейронных сетей (фото 1962 г.)
Источники:
• Галушкин, А. И. (1974). Синтез многослойных систем распознавания образов.
https://cat.gpntb.ru/?id=FT/ShowFT&sid=2fd4458e5ab8a6bfb401f07b8efc01cd&page=1&squery=
• Л. Н. Ясницкий («О приоритете советской науки…», журн. «Нейрокомпьютеры: разработка, применение», т. 21 № 1, с. 6-8)
https://publications.hse.ru/pubs/share/direct/317633580.pdf
• Ивахненко А.Г. (1969). «Самообучающиеся системы распознавания и автоматического управления»
• Вербос, П. (1974). Beyond Regression.
https://gwern.net/doc/ai/nn/1974-werbos.pdf

-
-
- +1
-
Зачем поддерживать автора?
Зачем поддерживать автора?
- - Любой текст это труд, если вам понравилась статья, то поддерживая автора - вы показываете, что оценили то, что он потратил свое время и силы.
- - Автор получает небольшую финансовую помощь от вас, у него появляется больше стимула сделать еще лучше.
- - Статья, которую поддерживают пользователи попадет в рейтинг по поддержке на главной странице Конта, что принесет ей больше просмотров и откликов, а значит, поддерживая статью вы помогаете автору продвигать его точку зрения.


















Оценили 26 человек
39 кармы